Debate
| Tópico | Tema 1 | Tema 2 | Tema 3 | Tema 4 | Tema 5 | Tema 6 | Tema 7 | Data |
|---|---|---|---|---|---|---|---|---|
| Hardware | Barramentos | Periféricos | Processadores | Portas | Memória RAM | Disco Rígido | Memória ROM | 09/05 |
| Software | App | ERP | Sistema Embarcado | Frameworks | Firmware | SO | Web | |
| Development | Algoritmos | API | Compiladores | IDE | Linguagens de Programação | Open Source | Webservice | |
| DataBase | Banco de Dados | Normalização | SQL | BigData | ETL | Data Mining | NoSQL | |
| Methods | Canvas | eXtreme Programming | Integração Contínua | Modelo Orientado a Serviço | Scrum | UML | FDD | |
| Net | Firewall | Internet | IP | Protocolos | Redes de Computadores | Roteador | DNS | |
| Cloud | Virtualização | Modem | DNS | Criptografia | Cloud Computing | Plataformas | SaaS | |
| Internet of Things | RFId | Raspberry | IPSec | IoT | CLP | Arduino | Sensores | |
| State of the Art | BlockChain | IA | Inteligência Cognitiva | Machine Learning | RA | Bots | Redes Neurais |
Tabela de Temas
| Nro | Tema | Tópico | Aluno |
|---|---|---|---|
| 01 | Algoritmos | Development | Giovana Campioto |
| 02 | API | Development | Gabriel Rodrigues |
| 03 | App | Software | Elton |
| 04 | Arduino | Internet of Things | Fábio |
| 05 | Banco de Dados | Database | Guilherme Rodovalho |
| 06 | Barramentos | Hardware | Pablo Pierre da Nóbrega |
| 07 | BigData | Database | Pedro Henrique Chagas |
| 08 | BlockChain | State of the Art | Arthur Maia |
| 09 | Bots | State of the Art | Mateus Gonçalves Canavieira |
| 10 | Canvas | Methods | Prof. Luiz Cláudio |
| 11 | Cloud Computing | Cloud Computing | Mateus Ferreira Silva |
| 12 | CLP | Internet of Things | Nathaly V |
| 13 | Compiladores | Development | Carlos Erivelton |
| 14 | Criptografia | Cloud Computing | Guimarães |
| 15 | Data Mining | Database | Samantha |
| 16 | Disco Rígido | Hardware | Marcello |
| 17 | DNS | Cloud Computing | Luís Fellipe de Souza |
| 18 | ERP | Software | Esdras |
| 19 | ETL | Database | Vinicius Prado |
| 20 | eXtreme Programming | Methods | Murilo Medeiros |
| 21 | FDD | Methods | Francisco dos Santos |
| 22 | Firewall | Net | João Pedro Silva Mendes |
| 23 | Firmware | Software | Pedro Henrique Zardini De Souza |
| 24 | Frameworks | Software | Lucas Henrique Couto |
| 25 | IA | State of the Art | Tonus |
| 26 | IDE | Development | Arthur Rodrigues Cardoso |
| 27 | Inteligência Cognitiva | State of the Art | Igor Medeiros |
| 28 | Integração Contínua | Methods | Carlos Henrique Duarte de Carvalho |
| 29 | Internet | Net | Brunno Viegas |
| 30 | IoT | Internet of Things | Nicolli Freitas |
| 31 | IP | Net | Gustavo Alves |
| 32 | IPSec | Internet of Things | Piedro Hammer |
| 33 | Linguagens de Programação | Development | Luís Humberto Rodrigues |
| 34 | Machine Learning | State of the Art | Rick Ricarte |
| 35 | Memória RAM | Hardware | Luiz André |
| 36 | Memória ROM | Hardware | Bryan Ernanes |
| 37 | Modelo Orientado a Serviço | Methods | Dyany |
| 38 | Modem | Cloud Computing | Pedro Alexandre |
| 39 | Normalização (BD) | Database | Wilson Santos |
| 40 | NoSQL | Database | João Victor |
| 41 | Open Source | Development | Fernando Daniel Silva |
| 42 | Periféricos | Hardware | Matheus Gonçalves Coelho de Resende Silvano |
| 43 | Plataformas | Cloud Computing | Augusto Cesar de Barros Silveira |
| 44 | Portas | Hardware/Net | Marco Túlio Candeo |
| 45 | Processadores | Hardware | Victor Buiatti |
| 46 | Protocolos | Net | Rafael Dutra |
| 47 | RA | State of the Art | Lucas Mezencio Santana |
| 48 | Raspberry | Internet of Things | Gabriel Ferreira de Souza |
| 49 | Redes de Computadores | Net | Gabriel Rafah |
| 50 | Redes Neurais | State of the Art | Thalison Henrique |
| 51 | RFId | Internet of Things | Henrique Matheus |
| 52 | Roteador | Net | Tiago Gomes |
| 53 | SaaS | Cloud | Rogério Aguilar Silva |
| 54 | Scrum | Methods | Gustavo Augusto Ferreira |
| 55 | Sensores | Internet of Things | Matheus de Camargo Martins |
| 56 | Sistema embarcado | Software | murilo ferreira |
| 57 | SO | Software | Marco Antonio da Silva Rodrigues |
| 58 | Speech Recognition | State of the Art | Igor Lourenço |
| 59 | SQL | Database | Ramon Maximo |
| 60 | UML | Methods | Bruno Giamatei Bertoco |
| 61 | Virtualização | Cloud Computing | Lucas Capra |
| 62 | Web | Software | Gabriel Marques |
| 63 | Webservice | Development | Vinicius Pereira |
Descrição dos temas
Algoritmos
- Noções de Algoritmos
Algoritmo é a base da ciência da computação e da programação. Quando falamos em programar, falamos, basicamente, em construir um algoritmo. Todo programa de um computador é montado por algoritmos que resolvem problemas matemáticos lógicos com objetivos específicos. Mesmo pessoas que usam uma linguagem de programação para fazer seus programas de computadores estão, na realidade, elaborando algoritmos computacionais em suas mentes. Um algoritmo não passa de passos sequenciais e lógicos que são organizados de forma a realizar a conclusão de certo problema. Mas precisamos entender que existem dois tipos de algoritmos, os Não Estruturados e os Estruturados. Programadores usam algoritmos estruturados, pois se adequam a determinado objetivo ou certo fim. Mas não são apenas os programadores que usam algoritmos. Em nosso cotidiano, os algoritmos Não Estruturados são trabalhados em nossas mentes sem nem mesmo percebermos.
- Algoritmos não estruturados
Em nossa rotina, executamos algoritmos sem perceber. Quando você levanta pela manhã, quando você sai de casa, quando almoça. Você está sempre executando tarefas enquanto realiza análises de decisões, análises de possibilidades, valida argumentos e diversos outros processos. Há muitos exemplos de algoritmos. Um deles são os manuais de instruções. Manuais de instruções sempre contêm informações detalhadas sobre o que fazer em cada situação e nos previnem de maiores problemas.
- Algoritmos Estruturados
São aqueles que buscam resolver problemas através do uso de um computador. São criados com base em uma linguagem de programação e podem ser escritos de diversas formas. Um algoritmo pode ser representado pelo chamado Português Estruturado, que é uma ferramenta que usa combinações de sequências, seleções e repetições. São evitados advérbios e adjetivos, formas verbais diferentes da imperativa, muita pontuação e descrição esparsa.
- Bibliografia
https://www.devmedia.com.br/nocoes-basicas-de-algoritmo/26405
API
- O que é?
- Segundo o Free Online Dictionary of Computing (1994) API é uma ferramenta que que realiza comunicação entre aplicações que desejam compartilhar suas rotinas, ferramentas, padrões e protocolos.
- Exemplificando de maneira mais simples: É uma espécie de mensageiro entre dois ou mais sistemas, exemplificando de maneira familiar, a API é como um garçom de um restaurante. O cliente, neste caso a aplicação que deseja receber os serviços, recebe do garçom o menu com todos os itens daquele restaurante. Ao escolher uma opção o garçom leva este pedido até a cozinha, aplicação da API, onde por sua vez os cozinheiros, que são os serviços compartilhados pela aplicação, realizam o pedido como foi descrito pelo cliente. Ao concluir o pedido o cozinheiro avisa o garçom, este por sua vez entrega o pedido ao cliente completando o processo de exemplificação uma requisição de API.
- Tipos de API.
- Atualmente, muitas API são baseadas em Serviços de webresidentes em hipertexto-padrão, as mais utilizadas no momento são as API baseadas em REST e SOAP.
- REST: Os Serviços web RESTful são qualquer serviço do grupo de abordagens que se molda aos princípios da arquitetura de Transferência de Estado Representativo (REST). Os princípios REST pedem uma arquitetura de cliente/servidor stateless geralmente com base em HTTP. Eles se moldam aos Indicadores de Recurso Universal (URI) e usam os métodos CRED de PUT, GET, POST e DELETE.
- SOAP: O Protocolo Simples de Acesso aObjetos (SOAP) baseado em Serviços de Web é baseado no protocolo WC3. O WC3 estabelece que o “SOAP é um protocolo mais leve para a troca de informações em um ambiente descentralizado e distribuído”. Geralmente está associado à Linguagem de Descrição de Serviços Web (WSDL) e UDDI. A WSDL é definida como uma linguagem baseada em XML para descrever os serviços web.
- Como funciona?

- Por que devemos desenvolver e utilizar API.
- Dentre diversos motivos, os principais que podemos citar, de acordo com Luckas Frigo do site Moblee, são:
- 1) Não ficar refém de uma tecnologia ou serviço.
- O primeiro motivo é não ficar refém de uma tecnologia específica. Pode ser a troca de banco de dados, de linguagem de programação ou um serviço de terceiros que pode deixar de existir.
- 2) Centralizar informações e regras de negócio.
- Parece bem óbvio e é a principal função de qualquer API, mas nós já passamos por casos em que o sistema que nós estávamos integrando não tinha uma API. Nós tínhamos acesso direto a um banco de dados. Agora imagina se nós estivéssemos na mesma situação: cada aplicação lendo e escrevendo do jeito ela acha melhor, sem uma API no meio para validar regras e garantir que os dados estão consistentes. Seria o caos.
- 2) Centralizar informações e regras de negócio.
- 3) Aplicar regras de integração customizada
- Gerenciar regras de integração customizadas. Como assim? Principalmente quando você tem um produto white-label, é necessário ter regras de integração diferentes para clientes diferentes. Por exemplo, nós temos um produto que é um leitor de contatos que coleta dados a partir da credencial do participante. Por isso, nós temos que integrar dados com diversos sistemas de credenciamento para conseguir conectar a informação da credencial com os dados do participante. Nesse processo, é bem comum acontecerem mudanças de última hora no formato do código da credencial. Como o processo de republicar um app é relativamente lento, não é possível garantir que todos os usuários estejam com a versão mais atualizada e fica a cargo da API conseguir contornar essas situações.
- 3) Aplicar regras de integração customizada
- 4) Autenticar o usuário em sistemas diferentes
- Como eu já citei, nosso produto é white-label e se integra com vários sistemas dependendo de cada cliente. Às vezes, não basta que o usuário faça login na nossa base, é preciso autenticá-lo no sistema do cliente também. Imagine ter que ensinar o seu app a se logar em cada sistema. Agora imagine se alguma regra de autenticação do sistema do cliente muda após o app já estar publicado. Seria uma dor de cabeça ter que republicar todos os aplicativos que dependem dessa integração. Por isso, contar com a API ajuda a manter a consistência das chamadas que o app faz e diminui a chance da sua republicação.
- 4) Autenticar o usuário em sistemas diferentes
- 5) Segmentar informações
- Existem vários casos em que você precisa segmentar informações de acordo com a aplicação que está solicitando-a. O CMS, por exemplo, precisa de informações que os apps não precisam. Eventualmente, pode ser preciso diferenciar informações para usuários de Android ou iOS. O envio de notificações é um caso de exemplo bem comum. Se precisamos publicar algum tipo de atualização crítica no app iOS e notificar aos usuários, não é necessário que os usuário de Android também recebam essa notificação. Essas regras de segmentação de informação quem cuida é a API.
- 5) Segmentar informações
- 6) Internacionalizar
- Internacionalizar costuma ser um problema para quem está crescendo internacionalmente. Nós temos aplicativos publicados em vários países e em várias línguas: português, inglês, espanhol… até mesmo tailandês. Independente de utilizar uma solução pronta de API ou ter a sua própria API, ela ajuda a manter a consistência entre dados internacionalizados. É bem comum acontecer dos nossos cliente traduzirem uma parte do conteúdo e deixar partes sem tradução. A API nos ajuda a manter a consistência, entregando a informação numa língua padrão, caso aquela informação não tenha sido ou não precise ser traduzida.
- 6) Internacionalizar
- 7) Dar suporte a versão antiga do app
- Quem nunca passou por isso, um dia vai passar. Continuamente sua aplicação vai ganhar novas funcionalidades e novas regras de negócio. O aplicativo dos usuários que não atualizarem para a última versão pode ficar inutilizável se a API não souber lidar com essas mudanças. Como você não controla quais usuários de fato fizeram atualização, fica difícil gerenciar esse tipo de coisa sem ter uma API responsável, pois é ela que mantém a consistência das regras de negócio.
- 7) Dar suporte a versão antiga do app
- 8) Controlar o endpoint
- Mesmo que você use um serviço como o Firebase por trás da sua API, é importante que você controle o endpoint, ou seja, a URL pela qual suas aplicações acessam a API. Isso reflete tanto a dependência de serviços de terceiros, quanto o suporte à atualização que comentamos.
- 8) Controlar o endpoint
- Referências Bibliográficas
App
- Conceito
- Aplicativo é um software que executar sequencias de comandos para realizar determinado objetivo pela qual foi projetado em um smartphone ou tablet.
- Ações executadas por aplicativos em sua maioria são para agilizar algum processo, diminuir custos ou substituir mão de obra.
- Aplicativos podem ser nativos ou híbridos.
- Aplicações nativas
- É aquele aplicativo que foi projetado para determinada plataforma. Ex: Android e IOS.
- Pode explorar o máximo do sistema operacional para qual foi desenvolvido.
- Caso o aplicativo tenha a necessidade ser executado em duas plataformas mobile (Android e IOS), então deve ser desenvolvido para cada plataforma separadamente.
- É uma ótima opção para clientes que desejam mais confiabilidade, segurança e comunicação direta com as funcionalidades do sistema operacional.
- Aplicações híbridas
- São aqueles aplicativos desenvolvidos tanto com códigos nativos quanto web, ou seja, podem desfrutar de recursos da internet e do sistema na qual está sendo executado.
- Não podem usar funcionalidades do dispositivo, sendo necessário o intermédio de um framework para ser possível a utilização de funcionalidades como por exemplo GPS e câmera.
- São mais rápidos e tem um custo de desenvolvimento menor do que aplicativos nativos. O tempo e custo reduzido é justificado pelo fato de ser necessário desenvolver aplicação apenas uma vez, já que o software roda em qualquer plataforma.
- Ferramentas de desenvolvimento
- Para o desenvolvimento dessas aplicações são utilizados algumas ferramentas como: editor de texto, IDE, framework, API, compilador, etc.
- Para desenvolver aplicações mobiles são utilizados em sua maioria IDEs e frameworks para agilizar e facilitar o processo de desenvolvimento.

- Ferramentas mais utilizadas
- Xamarin
- Android Studio
- Ionic
- React Native
- Unity
- Xcode
- Referências bibliográficas
Arduino
- O que é?
No site oficial da Arduino, encontramos a seguinte definição (traduzida): O Arduino é uma plataforma de código aberto (Logo, possui possui tanto hardware quanto software open source! expressão utilizada para denotar que o mesmo pode ser executado, copiado, modificado e redistribuído pelos usuários de forma livre) de prototipagem eletrônica com hardware e software flexíveis e fáceis de usar, destinado a artistas, designers, hobbistas e qualquer pessoa interessada em criar objetos ou ambientes interativos. Em termos simples, as placas Arduino são semelhantes à um minicomputador, no qual, pode-se programar a maneira como suas entradas e saídas devem se comportar em meio aos diversos componentes externos que podem ser conectados nas mesmas. Essas placas são plataformas essencialmente formadas por dois componentes: A placa, que é o Hardware que usaremos para construir nossos projetos e a IDE Arduino, que é o Software onde escrevemos o que queremos que a placa faça.
E agora a pergunta... Por que essa plataforma de desenvolvimento é tão usada? A maior vantagem dessa plataforma sobre as demais é a sua facilidade de utilização, pois, pessoas que não são da área técnica podem aprender o básico e criar seus próprios projetos em um intervalo de tempo relativamente curto.

- Como surgiu?
O Arduino foi um projeto que iniciou na Itália no ano de 2005 com o objetivo de ser uma plataforma de baixo custo e de fácil aprendizado, pois antigamente para se confeccionar um circuito interativo, era necessário fazer projetos do zero para uma aplicação específica. Além disso, para se fazer pequenas alterações nas funcionalidades do circuito era necessário um estudo crítico e bastante trabalho. Com a criação dos microcontroladores, foi possível que problemas que antes eram tratados com soluções de hardware fossem tratados usando software de computadores. Dessa forma, um mesmo circuito poderia desempenhar funções totalmente diferentes, através da reprogramação e alteração de alguns parâmetros do programa. No entanto, apesar da facilidade trazida pelos microcontroladores, trabalhar com os mesmos não era tão fácil. Desta forma, um grupo de pesquisadores italianos teve a ideia de fazer um dispositivo que tornasse o seu uso simples e acessível a qualquer um. O resultado foram as placas Arduino. Os desenvolvedores são: Massimo Banzi, David Cuartielles, Tom Igoe, Gianlica Martino e David Mellis.
- Como funciona?
Como já dito, os Arduinos possuem funcionamento semelhante ao de um pequeno computador capaz de interpretar entradas e controlar as saídas afim de criar sistemas automáticos. Para isso, você precisa programa-lo ou seja, falar ao controlador quais decisões devem ser tomadas em cada circunstância. Para isso, escrevemos um código que segue uma sequência lógica de tomada de decisões que leva em conta as variáveis que serão lidas e/ou controladas. Para programar essas placas, ou seja, ensiná-las a desempenharem a as funcionalidades que você deseja, basta utilizarmos a sua IDE (ambiente integrado de desenvolvimento), que por sua vez, é um software onde podemos escrever um código em uma linguagem denomidada Wiring, semelhante a C/C++, o qual, será traduzido, após a compilação, em um código compreensível pela nossa placa.
- Aonde podemos usá-lo? Quais são as aplicações possíveis?
Por exemplo, um uso simples de Arduino seria acender LED's (imagine aqueles usados na época de natal) de maneira alternada à criar um certo padrão. Nesse exemplo, o Arduino teve vários LED's e um botão conectados a ele. O circuito aguardaria até que o botão fosse pressionado, de modo que, uma vez pressionado o botão, ele acenderia os LED's fazendo os padrões estipulados no código.

Outro exemplo mais simples ainda, seria ligar uma lâmpada, funcionamento que poderia ser posteriormente estendido, por exemplo pela conexão de um sensor, como um sensor de movimento, para acender a lâmpada quando uma pessoa entrasse em um determinado local e a desligasse quando a pessoa saísse do mesmo. O que faria o processo de lâmpadas ligarem e desligarem, automaticamente! Imagine uma casa onde não houvesse interruptores e sim uma "rede de Arduinos" controlando todas as luzes... Outros inúmeros projetos podem ser feitos com essa plataforma, como um painel solar que se move de acordo com a incidência da radiação proveniente do sol, aumentando assim a produção energética; uma planta que manda uma mensagem no seu celular quando precisar ser regada, uma caixa de brinquedos aberta por leitura de impressão digital, um robô espião sem fio entre muitos outros. A imaginação é o limite!
- Quais os modelos mais famosos de placas Arduino?
Erro ao criar miniatura: Arquivo não encontrado
Existem muitos modelos de placas Arduino, mais muitos mesmo! A mas a mais popular é a Placa Arduino Uno que iremos usar como referência. Apesar de diferentes modelos, os projetos que programamos em um modelo podem ser facilmente adaptados para outro. Basta ficar atento para as particularidades de cada placa.
- Arduino Uno e seus componentes:

Microcontrolador: Microcontrolador: Esse é o cérebro do Arduino. Um computador inteiro dentro de um pequeno chip. Este é o dispositivo programável que roda o código que enviamos à placa.Existem várias opções de marcas e modelos de microcontroladores, nessas placas foram adotados os microcontroladores da Microchip, que inicialmente eram produzidos pela Atmel, mas especificamente a linha ATmega. O modelo UNO, por exemplo, usa o microcontrolador ATmega328.
Conector USB: Conecta a placa ao computador. É por onde o computador e o Arduino se comunicam com o auxílio de um cabo USB, além de ser uma opção de alimentação da placa.
Pinos de Entrada e Saída: Pinos que podem ser programados para agirem como entradas ou saídas fazendo com que o Arduino interaja com o meio externo. O UNO R3 possui 14 portas digitais (I/O), 6 pinos de entrada analógica e 6 saídas analógicas (PWM).
Pinos de Alimentação: Fornecem diversos valores de tensão que podem ser utilizados para energizar os componentes do seu projeto. Devem ser usados com cuidado, para que não sejam forçados a fornecer valores de corrente superiores ao suportado pela placa.
Botão de Reset: Botão que reinicia a placa.
Conversor Serial-USB e LEDs TX/RX: Para que o computador e o microcontrolador conversem, é necessário que exista um chip que traduza as informações vindas de um para o outro. Os LEDs TX e RX acendem quando o Arduino está transmitindo e recebendo dados pela porta serial respectivamente.
Conector de Alimentação: Responsável por receber a energia de alimentação externa, que pode ter uma tensão de no mínimo 7 Volts e no máximo 20 Volts e uma corrente mínima de 300mA. Recomenda-se 9V, com um pino redondo de 2,1mm e centro positivo. Caso a placa também esteja sendo alimentada pelo cabo USB, ele dará preferência à fonte externa automaticamente.
LED de Alimentação: Indica se a placa está energizada.
LED Interno: LED conectado ao pino digital 13.
Especificações da placa: Nesta placa o microcontrolador ATmega328 é utilizado, este dispõem de 32kb de memória flash e 2kb de SRAM. De maneira simples a memória flash é o local na qual nosso programa será salvo, já a SRAM é a memória na qual nossas variáveis serão salvas. A diferença básica entre esses dois tipos de memória é que a flash não perde seus dados caso o Arduino seja desligado ou reiniciado o mesmo não é válido para a SRAM.
- IDE Arduino:
Uma das grandes vantagens da plataforma Arduino está no seu ambiente de desenvolvimento, que usa uma linguagem baseada no C/C++, linguagem bem difundida, usando uma estrutura simples. Mesmo pessoas sem conhecimento algum em programação conseguem, com pouco estudo, elaborar programas rapidamente.

- Fontes de pesquisa:
- <https://edisciplinas.usp.br/mod/resource/view.php?id=1645987> Artigo Acadêmico
- <http://www.abenge.org.br/cobenge/arquivos/8/sessoestec/art1886.pdf>Artigo Acadêmico
- <https://www.arduino.cc> Site Ofical do Arduino
- <https://portal.vidadesilicio.com.br/o-que-e-arduino-e-como-funciona/>
Banco de Dados
- O que é?
- Um banco de dados é uma forma de armazenar informações em disco de uma forma estruturada. Banco de dados são conjuntos organizados de dados, que se relacionam com outros para criar uma informação e dar mais eficiência durante uma pesquisa ou estudo. Atualmente, os bancos de dados são a principal parte de um sistema de informação, pois é nele que está toda a informação que o sistema é alimentado. Os bancos costumam perdurar por vários anos ou até décadas sem alteração na sua estrutura. A principal aplicação é no controle de operações empresariais e no gerenciamento de informações de estudos.

- Principais ferramentas:
- Sistemas Gerenciadores de Banco de Dados (SGBD’s) ou em inglês Data Base Management System (DBSM), que como o nome sugere, são softwares de Gerenciamento de Banco de Dados, que são utilizados pelos programadores ou DBA’s, para consultar os bancos de dados. Com a evolução desses softwares, vários modelos de armazenamento de dados foram criados, como o Modelo hierárquico, Modelo em rede, modelo orientado a objetos e outros, cada um com suas particularidades, vantagens e desvantagens.

- Abstração de dados
- O sistema de banco de dados deve oferecer uma visão abstrata dos dados que lá estão armazenados, por exemplo, o usuário não precisa saber qual criptografia está sendo usada ou se está sendo usada, ele não precisa saber a normalização do banco, ele não precisa saber qual unidade de armazenamento está sendo utilizada, contando que quando ele precisar o dado esteja disponível para ele quando precisar. A abstração se dá em 3 níveis:
- Nível de visão do usuário: as partes do banco que o usuário tem acesso, de acordo com a necessidade individual.
- Nível Conceitual: aqui é definido quais dados estão armazenados, e qual o relacionamento entre eles.
- Nível físico: aqui define efetivamente como os dados estão armazenados, o nível mais baixo de abstração.
- Projeto de Banco de Dados
- Todo sistema de banco de dados deve apresentar um projeto da forma que os dados estão sendo armazenados a sua organização, e as técnicas utilizadas na produção do banco, para que no futuro facilite as possíveis manutenções. Esse projeto de banco de dados se dá em duas partes: projeto lógico e modelo conceitual. Essas fases são aplicadas na documentação de um banco de dados não implementado, no caso de ser um banco de dados já implementado, é utilizado a técnica de engenharia reversa para deduzir quais as técnicas que foram utilizadas para a produção desse banco.
- Referências bibliográficas
Barramentos
- É um conjunto de linhas de comunicação que permitem a interligação entre dispositivos, como a CPU, a memória e outros periféricos. Os barramentos podem ser chamados também de interfaces, portas, conectores, slots. Com a evolução do computador surgiram vários outros tipos de barramentos: USB, Firewire, Tunderbolt, Serial, PS/2, SuperVideo/VGA/HDMI. Os processadores mais modernos, sejam da Intel ou da AMD, possuem um barramento extremamente rápido para se comunicarem com a memória e assim transferirem dados sem perda de desempenho.

- Funções
- Comunicação de Dados: função de transporte dos dados. Tipo bidirecional;
- Comunicação de Endereços: função de indicar endereço de memória dos dados que o processador deve retirar ou enviar. Tipo unidirecional, e;
- Comunicação de Controle: função que controla as ações dos barramentos anteriores. Controla solicitações e confirmações. Tipo bidirecional.
- Tipos de Barramentos.
- Na arquitetura de computadores são caracterizados como síncronos e assíncronos.
- Barramento Sincrono:
- Barramento do Processador: É utilizado pelo processador internamente e para envio de sinais para outros componentes do sistema computacional.Atualmente, os barramentos dos processadores (os de transferência de dados) têm sido bastante aprimorados com o objetivo de maior velocidade de processamentos de dados.
- Barramento de Cache: É o barramento dedicado para acesso à memória cache do computador, memória estática de alto desempenho localizada próximo ao processador.
- Barramento de Memória: É o barramento responsável pela conexão da memória principal ao processador. É um barramento de alta velocidade que varia de micro para micro e atualmente gira em torno de 512 MHz a 8192 MHz, como nas memórias do tipo DDR3.
- Barramento de Entrada e Saída: É o barramento I/O (ou E/S), responsável pela comunicação das diversas interfaces e periféricos ligados à placa-mãe, possibilitando a instalação de novas placas, os mais conhecidos são: PCI, AGP e USB.
- Barramento de Dados: É o barramento Data Bus, responsável por transportar informação da instrução (através do código de operação), variável do processamento (cálculo intermediário de uma fórmula por exemplo) ou informação de um periférico de E/S (dado digitado em um teclado). O tamanho da via de dados determina respectivamente o máximo número de instruções (e portanto o potencial de processamento) e a precisão do processamento aritmético (através do cálculo de ponto flutuante) ou o número de símbolos possíveis a ser representado (por exemplo, pontos de uma foto).
- Barramentos assíncronos:
- Os barramentos assíncronos não possuem clock e por sua vez adotam um protocolo chamado de "aperto de mão" ou handshake para estabelecer a comunicação entre os dispositivos assim podendo ser mais adaptável a dispositivos novos ou lançamentos pois ele não possui velocidade fixa.
- Referências
https://americnet.wordpress.com/2010/03/18/tipos-de-barramentos-do-computador/ https://pt.wikipedia.org/wiki/Barramento https://www.hardware.com.br/livros/hardware/barramentos.html https://canaltech.com.br/hardware/O-que-e-um-barramento/ Infraestrutura de Hardware –Juliana Regueira Basto Diniz, Abner Corrêa Barros - Volume 2
BigData
Atualmente na informatica trabalhamos com uma amplitude gigante de dados, um sistema pode receber inúmeras informações (caso seja programado para tal) como quanto tempo o cursor ficou parado em um local, quanto tempo o usuário ficou em uma página. Essa chuva de informações podem ser importantes ou não, desse ponto de ideia surgiu o conceito de Big Data.
Big Data nada mais é do que a analise dos dados brutos gerados por um sistema para assim serem filtradas (garimpadas) as mais "importantes" , essas em menor volume e mais fáceis de serem trabalhadas.
Dentro das analises para Big Data existem 5 aspectos importantes a serem destacados, são eles velocidade, veracidade, valor, volume e variedade. O volume é a quantidade de dados a serem analisados (sempre em crescimento), a velocidade que os dados vão sendo gerados, a variedade de vários lugares onde os dados serão gerados, veracidade da informações, pois dependendo do local onde é gerado ou o tempo ela pode não ser mais verdade, por ultimo e talvez a mais importante seja o valor, qual a importância de um dos dados para meu sistema ou podem ser reaproveitamos em outro local, neste caso qual deve ser descartado ou guardado.
Muitas empresas acabam lucrando com a venda desses dados filtrados através de Big Data, um exemplo hipotético pode ser a Spotify vender informações onde um cantor é mais ouvido ou não, o cantor pode fazer um show onde é mais popular e investir em divulgações onde menos é ouvido. Muitas redes sociais trabalham com a Big Data para mostrar o que seu usuário quer ver.
- Referencias Bibliográficas
BlockChain
- O que é?
- Blockchain, uma das tecnologias por trás do Bitcoin, a maior criptomoeda já inventada. Basicamente um banco de dados online, público e descentralizado, criado para tornar a distribuição de informações transparente e confiável, não dependendo assim de um agente externo e/ou centralizador que valide o processo.
- Rede Peer-to-Peer (P2P)
- Formado por uma rede de computador interligados, conhecido como rede peer-to-peer. Cada criptomoeda possui sua própria Blockchain. Como dito antes, a tecnologia Blockchain é formada por uma rede peer-to-peer, que é nada mais que uma arquitetura de redes de computadores onde cada um dos pontos ou nós da rede funciona tanto como cliente quanto como servidor, permitindo compartilhamentos de serviços e dados sem a necessidade de um servidor central, como pode ser visto na imagem abaixo.

- Como funciona?
- Nesta tecnologia revolucionaria, os computadores da rede são responsáveis por validar as transações. No caso do Bitcoin, toda vez que uma transação é realizada, é verificada pelos membros da rede registrada no blockchain correspondente. Por intervalos regulares de tempos (o tempo varia sobre as criptomoedas, no caso da bitcoin, 10 minutos), essas novas transações são reunidas em blocos, criptografadas e adicionadas a uma cadeia de blocos (blockchain) que guarda e registra também as transações passadas.

- Vantagens
- Eliminação de troca por intermediário e falta de confiança;
- Empoderamento dos usuários;
- Alta qualidade de dados;
- Durabilidade, confiabilidade e longevidade;
- Integridade de processo;
- Transparência e imutabilidade;
- Simplificação de ecossistema;
- Transações mais rápidas;
- Menor custo por transação;
- Digital.
- Desvantagens
- Tecnologia nascente;
- Estado regulatório instável;
- Grande consumo de energia;
- Controle, segurança e privacidade;
- Questões de integração;
- Adoção cultural;
- Custo;
- Referencias Bibliográficas
Bots
- Bots são tipos específicos de programas de computadores implantados em outros sistemas para automatizar partes do funcionamento de um todo, realizando as tarefas de forma autônoma desde facilitar a navegação na internet até interagir com indivíduos, feito a partir de algoritmos que foram programados anteriormente. Os Bots são divididos em áreas dependendo do que fazem no programa, tem diversos e usados de formas variadas, como os crawlers, os chatbots e até usado em videogames

- Os conceitos para a realização desses softwares se iniciaram com Alan Turing ,que ,em 1950, definiu um conceito comum para o que seria Inteligência Artificial que até então era inexistente. Alan Turing elaborou então um teste que até hoje é utilizado para confirmar se uma máquina é ou não uma IA, o teste se baseava em um dialogo entre um ser humano e uma máquina e depois de algumas perguntas e respostas o ser humano não conseguisse distinguir que estava dialogando com uma máquina, tal poderia ser considerada verdadeiramente uma IA.
- Os Chatbots ferramentas software capazes de propor um diálogo com o ser humano em linguagem natural que foram fundamentados através do teste de Turing, o dialogo se desenvolve através da capacidade de compreensão do sistema e da simulação do comportamento humano. A concepção mais aceitada sobre os chatbots seria de Simon Laven que diz " ... um programa que tenta simular uma conversa escrita, e que tenta, pelo menos temporariamente, se parecer com um ser humano". Com isso percebemos que os objetivos dos chatbots e da IA, estão conectadas, no que se refere na proximidade com o comportamento humano.

- Os crawlers são programas automatizados e metódicos que faz downloads de páginas WEB para criar índices ou caches sobre as mesmas. É aplicado em diversas áreas desde obter informações até mesmo mapear uma gama de sites, sendo muito utilizado por empresas que possuem motores de busca em sites, como o Google e o Mozila Firefox.

- Fontes:
http://www.inf.ufsc.br/~luis.alvares/INE5644/G1_WebCrawlers.pdf
http://www.cin.ufpe.br/~tg/2016-2/jhcl.pdf
http://www.internetlab.org.br/wp-content/uploads/2018/07/Relat%C3%B3rio-Bots-ou-n%C3%A3o.pdf
Canvas
- O Business Model Canvas é uma ferramenta estratégica que contribui de forma significativa para a construção rápida e visual de novos produtos ou serviços. Sua aplicação consiste no uso de um painel dividido em nove grandes blocos, como mostra a figura abaixo, que representam os elementos fundamentais (building blocks) que compõem um modelo de negócio.
- O objetivo central do preenchimento do painel é extrair propostas de valor que atendam e potencializem os principais objetivos desejados do negócio, antes de partir de fato para a formatação do produto ou serviço.
- Abaixo apresentamos a dinâmica de montagem do Modelo Canvas sugerida por Osterwalder.

- Para aplicar o Canvas, pode-se utilizá-lo impresso em um tamanho A4 ou A3 para facilitar o trabalho colaborativo; ou desenhá-lo em um quadro, pois seu layout é simples de ser replicado. Para preencher o Canvas é recomendado utilizar post-its, pois são fáceis de manipular.
- O Canvas, que apresentamos na figura abaixo, pode ser subdividido em duas grandes dimensões, como nos lados direito e esquerdo do cérebro, sendo a dimensão mais à direita os elementos mais subjetivos e "emocionais" e os elementos da parte esquerda os mais estruturais e lógicos. Sugere-se preencher o Canvas da direita para a esquerda, pois assim é possível conhecer primeiro os anseios e desejos dos envolvidos para, em seguida, começar a defini-los de forma mais concreta.

- Segmentos de Clientes
- Começamos preenchendo o bloco Segmentos de Clientes (Customers Segments), buscando mapear para quem se está criando valor e quem são os potenciais clientes para os objetivos pretendidos.
- Exemplos de segmentos de clientes:
- Consumidores da classe C
- Mulheres
- Idosos
- Consumidores de uma cidade
- etc.
- Proposta de Valor
- No bloco Proposta de Valor (Value Proposition) são criadas propostas que atendam a determinadas necessidades dos potenciais clientes, sempre tendo os objetivos de negócio norteando a dinâmica.
- Exemplo de propostas de valor:
- Conveniência
- Personalização
- Apoio a decisão
- Rapidez
- Redução de custos
- entre outros.
- Os Segmentos de Clientes e as Propostas de Valor são os principais elementos, sobre os quais todo o restante do Canvas se apoiará.
- Canais de Distribuição
- Uma vez que já se tem uma prévia de clientes potenciais e propostas de valor, é necessário pensar em como fazer com que estes dois elementos fundamentais se encontrem.
- Logo, são definidos e sugeridos os Canais de Distribuição (Channels), como:
- Entrega à domicílio
- Site de conteúdo
- Newsletter
- Atendimento presencial
- entre outros
- através dos quais será possível distribuir e entregar as propostas de valor.
- Uma vez que já se tem uma prévia de clientes potenciais e propostas de valor, é necessário pensar em como fazer com que estes dois elementos fundamentais se encontrem.
- Relacionamentos com os Clientes
- Também é preciso entender como se dará os Relacionamentos com os Clientes (Customer Relationships), que deve ter o propósito de fortalecer o envolvimento do cliente com o negócio.
- São exemplos de relacionamentos com clientes:
- Canal de perguntas e respostas
- Ouvidoria
- SAC
- Atendimento pós-venda
- Serviços automatizados.
- Receita
- Por fim, na dimensão direita, temos as Linhas de Receita (Revenue Stream), que registram como a solução em construção pretende gerar receitas, tendo como base as propostas de valor sugeridas.
- Alguns exemplos:
- Venda de assinaturas mensais
- Venda direta
- Retorno em publicidade paga
- Aluguel.
- Recursos-Chave
- Na dimensão esquerda do Canvas encontramos algumas definições mais objetivas, que irão sustentar os elementos mapeados na dimensão direita.
- Os Recursos-Chave (Key Resources) são os recursos ligados diretamente ao funcionamento do modelo de negócio.
- Podem ser:
- Equipes
- Máquinas
- Investimentos
- Plataformas de tecnologia
- Atividades-Chave
- As Atividades-Chave (Key Activities) são todas as atividades sem as quais não seria possível atender as propostas de valor, construir os canais necessários e manter os relacionamentos.
- Podem ser atividades-chave:
- Acompanhar redes sociais (uma atividade interessante para contribuir com o relacionamento com os clientes)
- Construir uma loja (que pode se relacionar com as propostas de valor e canais específicos)
- Aprender uma tecnologia que serve de base para o desenvolvimento de uma solução
- Monitorar outras soluções para avaliar se a sua está dentro dos padrões;
- Parceiros-Chave
- Já os Parceiros-Chave (Key Partners) são todos aqueles que podem contribuir tanto com as Atividades-Chave quanto com os Recursos-Chave.
- Algumas parcerias:
- Fornecedores de Tecnolologia, podem disponibilizar máquinas para atender a algum Recurso-Chave.
- Algumas parcerias podem contribuir com pessoas ou realizando diretamente alguma das Atividades-Chave, como Monitorar redes sociais
- Outras podem fornecer uma plataforma que se conecta com a sua para prover o serviço final.
- Custos
- Representando os custos necessários para se manter e construir toda a solução proposta, há o bloco Estrutura de Custos (Costs Structure), que indica, por exemplo:
- a necessidade de se Pagar a manutenção das máquinas previstas,
- Pagamentos dos parceiros contratados,
- Custo recorrente de infraestrutura
- Custo das equipes envolvidas
- e assim por diante.
- Representando os custos necessários para se manter e construir toda a solução proposta, há o bloco Estrutura de Custos (Costs Structure), que indica, por exemplo:
- Exemplo de projeto:

- Referências bibliográficas:
- A Osterwalder, Y Pigneur, G Bernarda, A Smith - 2014 - books.google.com
- Professor Dale Brant
Cloud Computing
- Definição
- Cloud Computing ou Computação em nuvem é um termo para descrever um ambiente de computação baseado em uma imensa rede de servidores sejam estes virtuais ou físicos. Uma definição simples pode ser "um conjunto de recursos como capacidade de processamento, armazenamento, conectividade, plataformas, aplicações e serviços disponibilizados na Internet". O significado de nuvem hoje é certamente ligado a um lugar onde se pode armazenar dados e onde aplicações podem usar recursos computacionais da nuvem ou elas podem ser executadas lá.
- Vantagens
- Elasticidade: a computação em nuvem oferece elasticidade permitindo que as empresas usem o recurso na quantidade que forem necessários, aumentando e diminuído a capacidade computacional de forma dinâmica.
- Pagamento: o pagamento dos serviços em nuvem é pela quantidade de recurso utilizados (pay-per-use). Nesse estilo de pagamento a conta é cobrada de acordo uso de dados e com o número de acessos que seus dados armazenados na nuvem foram usados.
- Comodidade: muitas empresas utilizam da computação em nuvem para evitar a dor de cabeça de ter um data center próprio e seus próprios servidores, sendo assim tendo que se preocupar com detalhes como segurança, preservação, manutenção dos servidores.
- Segurança: a segurança da empresas que oferecem serviços de computação em nuvem utilizam de vários métodos de segurança, valendo destacar entre eles os backups das informações. Uma analogia interessante de se fazer seria com um banco, "Você entrega seu dinheiro pra o banco pois sabe que ele estará mais seguro no banco de que com você e quando necessita dele é só ir saca-lo"
- Referências bibliográficas:
- https://books.google.com.br/books?hl=pt-BR&lr=lang_pt&id=mvir2X-A2mcC&oi=fnd&pg=PA1&dq=cloud+computing+&ots=CaJo6HLNUq&sig=zC8_RdJfBYXgHZVU-LjeNiMeLQI#v=onepage&q&f=true
- http://seer.upf.br/index.php/rbca/article/view/3084
CLP
- O que é CLP ?
CLP é a sigla ara Controladores Lógicos Programados ou Programmable Logic Controllers (PLC) em inglês, são computadores responsáveis por executar funções especificas utilizando um programa carregado. CLPs se assemelham muito com Computadores comuns, porem são desenvolvidos para operar em ambientes agressivos, suportando vibrações, poeira e outras condições que poderiam danificar uma CPU normal, alem de permitir várias inserções de módulos de entrada e saída. Basicamente ele opera utilizando sinais analógicos ou digitais, sensores, módulos, chaveamentos, entre outros e sua estrutura é composta por 4 patamares: entradas e saídas, CPU, Backplane ou Rack com fonte de alimentação e seção de programa e é composto por CPI, Memoria RAM e RUN e Portas de Comunicações (COM).
- Sinais analógicos e digitais
Sinais digitais são sinais que possuem apenas 2 (duas) variações de status (botões que permitem que o aparelho seja ligado ou desligado por exemplo), são sinais mais simples também chamados de contínuos por serem específicos e darem resultados previsíveis. Já os sinais analógicos possuem uma configuração mais complexa que permite um status variante com valores intermediários entre um minimo e um máximo ( como um termômetro de medição que emite valores diversos, não se atendo somente a 0 ou 100). Em uma CLP, esses sinais são cruciais na decisão do tipo de entrada e saída que irá ocorrer.
- Backplane ou Rack com fonte de alimentação
O RACK têm a função de interconetar todas as partes da CLP e permitir a alimentação e comunição entre elas, ele fornece montagem física para as In/Out (entradas e saídas) e conexão eletrica dos barramentos entre modulos(barramentos de dados que estabelecem um link de comunicação entre todos os modulos de In/Out AAbaixo pode-se ver um RACK com expansão e logo abaixo um Rack com CPU;


- Cartão de Entradas e Saidas (In/Out)
O Cartão de entradas é qualquer coisa que possa permitir a entrada de um sinal ao CLP e permitir a execução do programa, podendo ser de sinal analogico ou digital
- veja um exemplo abaixo:

As Saídas tambem podem ser de sinais analogicos ou digitais: ao se ter uma entrada analogica ela vai converter o sinal para digital que ao ser processado será enviado para um cartão de saida analogica que transformara esse sinal em analogico ou vice versa. eles servem para fazer acionamento simples como ligar lampadas ou valvulas etc.
- veja um esquema de entradas e saidas abaixo:

- CPU
É basicamente o cerebro da CLP e atua em quatro modos: Programação, Run, Stop e Reset
- No modo Programação a CPU faz o carregamneto da logica do programa desenvolvido por uma pessoa
- Após entra em modo Run em que está completamente operante com as funções do programa
- No modo Stop a CPU está parada e náo opera, desligando todas as saidas e checando as entradas
- No modo Reset a CPU é reiniciada para as configurações iniciais, caso seja feito sem eliminar os dados registrados é chamado de Warm Reset, caso os dados sejam apagados é chamado de Cold Reset
- Programa
é desenvolvido por uma pessoa em um computador proprio para CLP, a maioria das CLPs usa a linguagem Ladder, desenvolvida para facilitar a programação. O programa define oque será feito pela CLP
- Referencias
- https://alfacompbrasil.com/2019/02/11/clp-o-que-e-e-como-funciona/
- https://www.citisystems.com.br/clp/
- https://www.youtube.com/watch?v=RnYqTpuLWAA
- http://saladaautomacao.com.br/clp/
- https://www.saladaeletrica.com.br/o-que-e-clp/
Compiladores
Definição
- O que são compiladores ?
Um compilador nada mais é que uma aplicação com a função traduzir programas. Basicamente ele pega programa desenvolvido em uma linguagem de alto nível e o transforma em seu correspondente em baixo nível.
Um compilador é um software complexo, que cumpre o papel de traduzir, converter e ligar um programa escrito em linguagem de programação ou linguagem fonte em um programa de linguagem de máquina ou linguagem objeto. Ou seja, converte um programa escrito em linguagem de programação para uma linguagem cuja o computador entenda. No início, os compiladores não traduziam diretamente a linguagem fonte para a linguagem objeto, fazendo-se necessária a tradução em uma linguagem simbólica (Assembly), para que a partir de tal seja feita a tradução em linguagem objeto. Concluímos então que os compiladores são de suma importância nos tempos atuais, sabendo que cada vez mais há o estreitar da relação homem/máquina, sendo os compiladores hoje, peça fundamental de diálogo e aprimoramento das tecnologias que surgem atualmente.

- Referências:
- Santos ,Pedro Reis; Langlois ,Thibault. Compiladores - da teoria à prática. 1° edição, FCA editora, 2014.
- https://www.dicio.com.br/compilador/
- http://www.dca.fee.unicamp.br/~eleri/ea876/04/cap3.pdf
- http://producao.virtual.ufpb.br/books/tautologico/compiladores-livro/livro/livro.pdf
Criptografia
- Conceito
- Ferramenta de segurança digital utilizada em programação com o objetivo de proteger as informações de um arquivo. Tal instrumento de proteção garante quase por completo o bloqueio do acesso de terceiros ou usuários indesejados. Outrossim, o termo criptografia não é recente, pois surgiu na Grécia Antiga, kryptós (oculto/escondido) e gráphein (escrita/textos). Porém, como toda sociedade evolui e moderniza, tanto o instrumento como a sua definição passou por aprimoramento, portanto, a preservação de dados é crucial nos dias atuais.

- Tipos de Criptografia

- Criptografia Simples (SSL)
- Programa de proteção simples que garante a validação de medidas de segurança de um domínio, tal programa é recomendado para todo site mesmo que próprio não armazene dados do usuário. A maneira mais fácil de reconhecer se o site utiliza o SSL é procurar pelo ícone de um cadeado verde ao lado da URL, isso significa, criptografia simples ativa.
- Criptografia de Validação Estendida (SSL EV)
- Uma versão aprimorada do SSL extremamente recomendada para sites de comércio eletrônico.
- Certificado WildCard
- Diferente do SSL o WildCard protege não só o domínio principal, como também os sub-domínios em um só certificado. Essa criptografia é destinada a administradores de várias páginas ou sites.
- Certificado Multidomínio (MDC)
- Direcionado para empresas que possuem diversos domínios, pois o MDC assegura a defesa digital de até 210 domínios em um só certificado (SSL), sobretudo, todos são validados com HTTPS.
- Certificado Multidomínio EV (MDC EV)
- Uma versão aprimorada do MDC com enfoque na razão social da empresa.
- Certificado Multidomínio SAN (UCC)
- O UCC funciona apenas para aplicações Microsoft, no mais, não há diferenças notórias em relação a certificado de proteção.
- Certificado CodeSigning
- Criptografia voltada para a assinatura digital dos desenvolvedores/programadores no código fonte do software. Tal certificado assegura o projeto do desenvolvedor, pois é protegido contra edições e compartilhamentos de terceiros. O CodeSignin aceita códigos nos formatos: JAVA, Microsoft, Adobe, IOS, Android e Windows Phone.
- Criptografia para e-mails (S/MIME)
- Assemelha-se ao CodeSigning, no entanto, a ferramenta S/MIME é exclusiva na criptografia e assinatura digital de emails, diferente do item acima que age apenas no código fonte da aplicação. Torna-se imprescindível o uso do S/MIME porque por mais que os servidores possuam certificados digitais, criptografia de ponta, hackers ainda podem invadir o banco de dados e interceptar mensagens, consequentemente, um email sem proteção pode facilmente ser adulterado ou ter um conteúdo sigiloso vazado/exposto. Portanto, toda medida de segurança é viável, no segmento tecnológico programação quanto mais barreiras forem construídas mais protegido estará o sistema, código ou email.
- Criptografia simétrica
- Baseia-se na criação de uma chave única de acesso disponibilizada para o público ou grupo privado. Para acessar o conteúdo criptografado basta inserir a key, no entanto, há uma falha na criptografia simétrica na geração de chaves na proporção do número de visualizadores. Além disso, essa ferramente não verifica a integridade da identidade do usuário abrindo margem para ataques hackers. Portanto, mesmo que haja quebra de sigilo basta gerar outra chave, porém como foi mencionado é uma criptografia não recomendada.
- Criptografia assimétrica
- Opera em torno de duas chaves de acesso, uma chave específica para cifração e outra para decifração, uma key não é gerada a partir de outra, senão será uma criptografia simétrica. A cifração é pública, porém a privada é extremamente restrita para decifrar o código, sendo gerenciada apenas por um seleto grupo. Ademais, a autenticidade é um mecanismo presente nessa ferramenta, possibilitando a exclusividade de apenas uma chave de acesso por pessoa.
- Hashing
- É um algoritmo matemático que transforma qualquer bloco de dados em uma série de caracteres de comprimento fixo. Independentemente do comprimento dos dados de entrada, o mesmo tipo de hash de saída será sempre um valor hash do mesmo comprimento. Cada caractere da senha será modificado por outro caractere do corpo da hash. Ademais, há um fato curioso: as hashs podem ser lidas ou identificadas em cadeias para determinar a integridade do arquivo e se possui certificados ativos, exemplificando, em março de 2014, o DropBox bloqueou o compartilhamento de um determinado arquivo protegido, na época foi questionada por estar violando a privacidade dos usuários, todavia não houve invasão de privacidade, mas sim a leitura da hash no banco de dados. Mediante isso, pôde analisar os certificados de proteção ativos naquele determinado arquivo.
- Criptografia Simples (SSL)
- Como Criptografar?
- Há duas opções mais comuns de criptografar. Primeira, usar ferramentas já existentes criada por um programador, como por exemplo, FlashCrypt, AxCrypt, DiskCryptor,Gpg4win, 7-Zip e várias outras disponíveis na surface web. Essas ferramentas gerarão chaves de acesso para abrir o arquivo desejado (imagens, documentos, vídeos, pdfs, etc). Lembrando que, toda vez que o arquivo for aberto será solicitado a key. Segundo, criar o próprio mecanismo de proteção usando a linguagem que julgar melhor, desde que, haja no mínimo 128 bits nas keys. Portanto, criptografia não é uma funcionalidade incomum, tampouco irrelevante, pelo contrário, é um instrumento digital extremamente necessário nos dias de hoje, principalmente para usuários comuns porque realizam transferência de dados importantes em vias públicas de acesso sem proteção alguma.
- Referências bibliográficas
- https://www.kaspersky.com.br/resource-center/definitions/encryption
- https://www.devmedia.com.br/criptografia-conceito-e-aplicacoes-revista-easy-net-magazine-27/26761
- https://it-eam.com/criptografia-de-dados-por-que-e-tao-relevante-para-sua-empresa/
- https://www.isbrasil.info/blog/8-tipos-de-criptografia-que-voce-precisa-conhecer.html
- https://www.hostinger.com.br/tutoriais/como-funciona-o-ssh/#Entendendo-diferentes-tecnicas-de-criptografia
- https://dual.studio/certificados.php
- https://alphaservers.com.br/whmcs/index.php?rp=/store/ssl-certificates/wildcard
- https://www.rapidssl.com.br/certificado-code-signing
- https://www.globalsign.com/pt-br/blog/o-que-e-smime/
- https://docs.microsoft.com/pt-br/office365/securitycompliance/s-mime-for-message-signing-and-encryption
- https://www.segurisoft.com.br/criptografia/top-10-software-criptografia/
- https://www.devmedia.com.br/como-funciona-a-criptografia-hash-em-java/31139
- https://cryptoid.com.br/banco-de-noticias/29196criptografia-simetrica-e-assimetrica/
- https://blog.validcertificadora.com.br/assinatura-digital-e-hash-sao-mesma-coisa/
Data Mining
- O que é?
Data mining, ou mineração de dados, é a prática de examinar dados que já foram coletados – utilizando diversos tipos de algoritmos, normalmente de forma automática –, a fim de gerar novas informações e encontrar padrões. Considerando que minerar dados é um processo de transformar dados em informações úteis (dados mais valiosos a partir de dados complexos). Para atingir esse objetivo, alguns passos são realizados, como: encontrar padrões, associações e anomalias gerais nos dados. Em data mining não importa a forma como os dados foram coletados, se via banco de dados, 'web scraping', API's, etc.

- Técnicas no Data Mining
O Data Mining (DM) descende fundamentalmente de 3 linhagens. A mais antiga delas é a estatística clássica. Sem a estatística não seria possível termos o DM, visto que a mesma é a base da maioria das tecnologias a partir das quais o DM é construído.
A segunda linhagem do DM é a Inteligência Artificial (IA). Essa disciplina, que é construída a partir dos fundamentos da heurística, em oposto à estatística, tenta imitar a maneira como o homem pensa na resolução dos problemas estatísticos.
E a terceira e última linhagem do DM é a chamada machine learning, que pode ser melhor descrita como o casamento entre a estatística e a Inteligência Artificial. Enquanto a Inteligência Artificial não se transformava em sucesso comercial, suas técnicas foram sendo largamente cooptadas pela machine learning, que foi capaz de se valer das sempre crescentes taxas de preço/performance oferecidas pelos computadores nos anos 80 e 90, conseguindo mais e mais aplicações devido às suas combinações entre heurística e análise estatística. Machine learning é uma disciplina científica que se preocupa com o design e desenvolvimento de algoritmos que permitem que os computadores aprendam com base em dados, como a partir de dados do sensor ou bancos de dados. Um dos principais focos da Machine Learnig é automatizar o aprendizado para reconhecer padrões complexos e tomar decisões inteligentes baseadas em dados.
- Informações obtidas pelo Data Mining
- Associações: São ocorrências ligadas a um único evento. Por exemplo:um estudos de modelos de compra em supermercados pode revelar que, na compra de salgadinhos de milho, compra-se também um refrigerante tipo cola em 65% das vezes: mas, quando há uma promoção, o refrigerante é comprado em 85% das vezes.Com essas informações, os gerentes podem tomar decisões mais acertadas pois aprenderam a respeito da rentabilidade de uma promoção.
- Sequências: Na sequência os eventos estão ligados ao longo do tempo. Pode-se descobrir, por exemplo, que quando se compra uma casa, em 65% as vezes se adquire uma nova geladeira no período de duas semanas; e que em 45% das vezes, um fogão também é comprado um mês após a compra da residência.
- Classificação: Reconhece modelos que descrevem o grupo ao qual o item pertence por meio do exame dos itens já classificados e pela inferência de um conjunto de regras. Exemplo: empresas de operadoras de cartões de crédito e companhias telefônicas preocupam-se com a perda de clientes regulares, a classificação pode ajudar a descobrir as características de clientes que provavelmente virão abandona-las e oferecer um modelo para ajudar os gerentes a prever quem são, de modo que se elabore antecipadamente campanhas especiais para reter esses clientes.
- Aglomeração (clustering): Funciona de maneira semelhante a classificação quando ainda não foram definidos grupos. Uma ferramenta de data mining descobrirá diferentes agrupamentos dentro da massa de dados. Por exemplo ao encontrar grupos de afinidades para cartões bancários ou ao dividir o banco de dados em categorias de clientes com base na demografia e em investimentos pessoais.
- Prognóstico: Embora todas essas aplicações envolvam previsões, os prognósticos as utilizam de modo diferente. Partem de uma série de valores existentes para prever quais serão os outros valores. Por exemplo um prognóstico pode descobrir padrões nos dados que ajudam os gerentes a estimar o valor futuro de variáveis com números de vendas.
- Ramificações
O Data Mining é um campo que compreende atualmente muitas ramificações importantes. Cada tipo de tecnologia tem suas próprias vantagens e desvantagens, do mesmo modo que nenhuma ferramenta consegue atender todas as necessidades em todas as aplicações. Algumas das ramificações do Data Mining são:
- Redes neurais: são sistemas computacionais baseados numa aproximação à computação baseada em ligações. Nós simples (ou "neurões", "neurônios", "processadores" ou "unidades") são interligados para formar uma rede de nós - daí o termo "rede neural". A inspiração original para esta técnica advém do exame das estruturas do cérebro, em particular do exame de neurônios. Exemplos de ferramentas: SPSS Neural Connection, IBM Neural Network Utility, NeuralWare NeuralWork Predict.
- Indução de regras: a Indução de Regras, ou Rule Induction, refere-se à detecção de tendências dentro de grupos de dados, ou de “regras” sobre o dado. As regras são, então, apresentadas aos usuários como uma lista “não encomendada”. Exemplos de ferramentas: IDIS da Information Discovey e Knowledge Seeker da Angoss Software.
- Árvores de decisão: baseiam-se numa análise que trabalha testando automaticamente todos os valores do dado para identificar aqueles que são fortemente associados com os itens de saída selecionados para exame. Os valores que são encontrados com forte associação são os prognósticos chaves ou fatores explicativos, usualmente chamados de regras sobre o dado. Exemplos de ferramentas: Alice d’Isoft, Business Objects BusinessMiner, DataMind.
- Analise de séries temporais: a estatística é a mais antiga tecnologia em DM, e é parte da fundação básica de todas as outras tecnologias. Ela incorpora um envolvimento muito forte do usuário, exigindo engenheiros experientes, para construir modelos que descrevem o comportamento do dado através dos métodos clássicos de matemática. Interpretar os resultados dos modelos requer “expertise” especializada. O uso de técnicas de estatística também requer um trabalho muito forte de máquinas/engenheiros. A análise de séries temporais é um exemplo disso, apesar de freqüentemente ser confundida como um gênero mais simples de DM chamado “forecasting” (previsão). Exemplos de ferramentas: S+, SAS, SPSS.
- Visualização: mapeia o dado sendo minerado de acordo com dimensões especificadas. Nenhuma análise é executada pelo programa de DM além de manipulação estatística básica. O usuário, então, interpreta o dado enquanto olha para o monitor. O analista pode pesquisar a ferramenta depois para obter diferentes visões ou outras dimensões. Exemplos de ferramentas: IBM Parallel Visual Explorer, SAS System, Advenced Visual Systems (AVS) Express - Visualization Edition.
- Sitografia
Disco Rígido
- Conceito
- O disco rígido, ou HD (Hard Disk), é o dispositivo de armazenamento permanente de dados mais utilizado nos computadores. Nele, são armazenados desde os seus arquivos pessoais até informações utilizadas exclusivamente pelo sistema operacional.
- O disco rígido não é um tipo dispositivo de armazenamento novo, mas sim um aparelho que evoluiu com o passar do tempo.
- Componentes e funcionamento
- Placa lógica
- A placa lógica reúne componentes responsáveis por diversaas tarefas. Um deles é um chip conhecido como controlador, que gerencia uma série de ações, como a movimentação dos discos e das cabeças de leitura/gravação, o envio e recebimento de dados entre os discos e o computador, e até rotinas de segurança.
- Outro dispositivo comum à placa lógiva é um pequeno chip de memória conhecido como buffer, visto mais abaixo. Cbe a ele a tarefa de armazenar pequenas quantidades de dados durante a comunicação com o computador.

- Discos

- Pratos e eixo : os pratos são os discos onde os dados são armazenados. Eles são feitos, geralmente, de alumínio recoberto por um material magnético e por uma camada de material protetor. Quanto mais denso for o material magnético, maior é a capacidade de armazenamento do disco. Os discos ficam posicionados sob um eixo responsável por fazê-los girar. É comum encontrar HDs que giram a 7.200 RPM, mas também há modelos que alcançam a taxa de 10.000 rotações.
- Cabeça e braço: os HDs contam com um dispositivo chamado cabeça de leitura e gravação. Trata-se de um item de tamanho bastante reduzido que contém uma bobina que utiliza impulsos magnéticos pra manipular as moléculas da superfície do disco e assim gravar dados. A cabeça é localizada na ponta de um dispositivo denominado braço, que tem a função de posicionar os cabeçotes acima da superfície dos pratos.
- Atuador: é o responsável por mover o braço acima da superfície dos pratos e assim permitir que as cabeças façam o seu trabalho. O trabalho entre esses componentes precisa ser bem feito. O simples fato de a cabeça de leitura e gravação encostar na superfície de um prato é suficiente para causar danos a ambos.
- Gravação e leitura de dados
- A superfície de gravação dos pratos é composta por materiais sensíveis ao magnetismo (geralmente, óxido de ferro). O cabeçote de leitura e gravação manipula as moléculas deste material por meio de seus polos. Para isso, a polaridade das cabeças muda em uma frequência muito alta: quando está positiva, atrai o polo negativo das moléculas e vice-versa. De acordo com esta polaridade é que são gravados os bits (0 e 1). No processo de leitura de dados, o cabeçote simplesmente "lê" o campo magnético gerado pelas moléculas e gera uma corrente elétrica correspondente, cuja variação é analisada pelo controlador do HD para determinar os bits. Para a "ordenação" dos dados no HD, é utilizado um esquema conhecido como geometria dos discos. Nele, o disco é "dividido" em cilindros, trilhas e setores:

- As trilhas são círculos que começam no centro do disco e vão até sua borda, como se estivessem um dentro do outro. Cada trilha é dividida em trechos regulares chamados de setores. Cada setor possui uma capacidade determinada de armazenamento (geralmente, 512 bytes).
- HDs externos
- É possível encontrar vários tipos de HDs no mercado, desde os conhecidos discos rígidos para instalação em desktops, passando por dispositivos mais sofisticados voltados ao mercado profissional (ou seja, para servidores), chegando aos cada vez mais populares HDs externos.
- HD externo simplesmente é um HD que você pode levar para praticamente qualquer lugar e conectá-lo ao computador somente quando precisar. Para isso, pode-se usar, por exemplo, portas USB, FireWire e até SATA externo, tudo depende do modelo do HD.

- referências bibliográficas:
DNS
- Definição
- DNS é a abreviação de Domain Name System (Sistema de Nome de Domínios). Sua função é interligar um domínio (o nome de um site como google.com, por exemplo) e um número de IP (uma sequência numérica como 210.128.0.23, por exemplo), que é a identificação do servidor correspondente ao domínio.
Criado na década de 80 para permitir a expansão das redes de computadores baseadas em TCP/IP, esse sistema subtituiu a rede antes utilizada chamada ARPANET. Esta Rede possuía um único arquivo de texto contendo uma tabela que relacionava os domínios com seus respectivos IPs. Porém, essa rede se tornou inviável à medida que mais e mais computadores entravam para a rede, pois a manutenção e atualização desse arquivo se mostraram trabalhosas.
- Diferente de sua antecessora, o DNS possui vários servidores com cópias dos arquivos distribuídos pelo mundo, cada um com uma cópia do enorme banco de dados de IPs registrados. O DNS traduz o domínio pelo qual o usuário procura na barra de endereços para números de IP.

- Como Funciona
- O banco de dados do DNS é organizado de forma hierárquica. Inicialmente, temo o chamado servidor raiz (root server). Este é automaticamente o principal serviço de DNS. Sua representação pode ser observada sempre que existe um ponto final no endereço, como no domínio www.google.com. Mas não é necessária a digitação desse ponto, uma vez que o sistema já reconhece o domínio mesmo não os introduzindo. A internet mundial possui 13 root servers no mundo todo. Assim, se um servidor parar, os outros manterão a estabilidade da função. Logo após o tipo “raiz”, vem o domínio de alto nível (Top Domain Level/TDL), sendo representado pelos servidores que abrigam os sites com final “.gov, .edu, .org, .net, .com, .br, .uk etc”. O tipo “com autoridade” é o último deles e, como o nome supõe, esse tipo de servidor DNS é estabelecido para fins próprios.
- Os root servers reconhecem todos os endereços de todos os outros servidores do tipo TDL. O sistema foi dividido dessa forma para evitar que uma falha em algum dos servidores inviabilize as conexões de rede.
- O sistema de DNS é parte fundamental da estrutura da internet, pois é o sistema que interliga o domínio ao seu destino, sem a necessidade de digitar sentenças numéricas extensas (IPs) todas as vezes que se quer buscar por algum endereço.
- Bibliografia
ERP
O que é?
- De forma geral, o ERP(Enterprise Resource Planning ou Planejamento dos Recursos da Empresa) representa uma série de atividades gerenciadas por um software ou por pessoas, que ajudam na gestão de processos dentro de uma empresa. Portanto, ERP é um Sistema de Gestão Empresarial.
- Uma das principais características dos sistemas ERP é justamente serem sistemas integrados, que permitem interligar e coordenar as atividades internas da empresa.

Alguns impactos nas empresas:
- A adoção de sistemas ERP transforma a empresa em pelo menos três maneiras:
- A terceirização do desenvolvimento de aplicações transacionais, reduzindo custos de informática;
- A implementação de um modelo de empresa integrada e centralizada;
- E a mudança da visão departamental para a visão de processos, por meio dos modelos disponibilizados pelo sistema.
Vantagens e desvantagens:
- PACOTE COMERCIAL:
- Pontos positivos nos aspectos organizacionais:
- Foco na atividade principal da empresa;
- Possibilitar a reorganização dos processos, utilizando informações de outras empresas acumuladas no sistema;
- Redução dos custos de informática;
- Foco por parte da Tecnologia da Informação para soluções empresariais, alterando o foco no desenvolvimento de sistemas.
- Pontos negativos:
- Dependência do fornecedor;
- Problemas de adaptação do pacote à empresa;
- Necessidade de alterar os processos da empresa;
- Necessidade de utilização de consultoria para implementação;
- Resistência a mudanças;
- Tempo para adaptação às interfaces desenvolvidas não especificas para a empresa;
- Possíveis incompartibilidade entre a estratégia da empresa e a lógica do ERP.
- Pontos positivos nos aspectos tecnológicos:
- Atualização de tecnologia;
- Contar com ganho de escala na pesquisa de novas tecnologias;
- Ganho de escala no tempo para desenvolvimento do sistema;
- Redução do backlog de aplicações;
- Ganho de uma infra-estrutura pela qual torna-se possível desenvolver os sistemas que a empresa precisa para diferenciar-se.
- Pontos negativos:
- Falta de controle sobre a evolução tecnológica do sistema;
- O conhecimento a respeito do funcionamento do pacote não está na empresa;
- Grandes mudanças no modelo de desenvolvimento e necessidades da equipe de TI, sendo necessário um retreinamento;
- Desafios em manter todo o conhecimento a respeito do funcionamento do pacote após a implementação;
- Nem todas as necessidades da empresa estarão disponíveis no pacote, sendo necessária a integração com outros sistemas.
- Pontos positivos nos aspectos organizacionais:
- INTEGRAÇÂO
- Pontos positivos nos aspectos organizacionais:
- Redução de mão-de-obra;
- Disponibilidade de maior controle sobre a operação da empresa, disponbilizado pela integração dos processos;
- Entrada única de informação no sistema;
- Maior velocidade nos processos;
- Aumentar a competitividade da empresa através da integração das atividades;
- Disponibilização online de informações alimentadas no sistema.
- Pontos negativos:
- Mudança cultural da visão departamental para a visão de processos;
- As decisões devem ser tomadas em grupo, visto que todos os departamentos estarão integrados no mesmo sistema;
- Entrada de dados incorretos pode ser imediatamente propagada pelo sistema;
- Altos custos e prazos de implementação.
- Pontos positivos nos aspectos tecnológicos:
- Desfragmentação dos sistemas de informação da empresa;
- Eliminação de interfaces entre sistemas isolados;
- Eliminação da necessidade de manutenção em diversos sistemas isolados e diferentes.
- Pontos negativos:
- Maior preocupação sobre a disponibilidade do sistema, podendo ocasionar uma interdependência entre os módulos;
- Maior dificuldade para fazer a atualização de versões e alterações no sistema, devido à necessidade de acordo entre os departamentos envolvidos.
- Pontos positivos nos aspectos organizacionais:
- ABRANGÊNCIA FUNCIONAL
- Pontos positivos nos aspectos organizacionais:
- Processos e procedimentos padronizados;
- Custos de treinamento reduzidos.
- Pontos negativos:
- Dependência de um único fornecedor em um sistema para o objetivo da empresa.
- Pontos positivos nos aspectos tecnológicos:
- Um único sistema e interface para toda a empresa;
- Redução dos custos de operação.
- Pontos negativos:
- Maior preocupação sobre a disponibilidade do sistema, pelo fato da empresa depender de um único sistema para funcionar.
- Pontos positivos nos aspectos organizacionais:
- BANCO DE DADOS CORPORATIVO
- Pontos positivos nos aspectos organizacionais:
- Padronização de informações;
- Eliminação de produção desnecessária de mesma informação produzida por departamentos distintos;
- Melhoria na qualidade da informação disponibilizada;
- Entrada única de informação no sistema;
- Disponibilização de informações gerenciais para análise de empresa como um todo.
- Pontos negativos:
- Mudança cultural da visão departamental para a visão de processos;
- As decisões devem ser tomadas em grupo, visto que todos os departamentos estarão integrados no mesmo sistema;
- Entrada de dados incorretos pode ser imediatamente propagada pelo sistema.
- Pontos positivos nos aspectos tecnológicos:
- Possibilidade de extrair informações utilizando ferramentas Desktop;
- Eliminação de redundâncias no banco de dados;
- Eliminação de duplicidade de esforços na entrada de dados.
- Pontos negativos:
- Maior dificuldade para fazer atualizações e alterações no sistema devido à necessidade de haver acordo entre todos os departamentos, visto que todos dependem do mesmo sistema para funcionar.
- Pontos positivos nos aspectos organizacionais:
Exemplo:
- Uma empresa precisa gerenciar contas a pagar e a receber, vendas e pedidos, folhas de pagamentos de funcionários, controle de estoque de mercadosrias, entre vários outros processos. Deixando cada processo destes nas mãos de diferentes departamentos, acaba elevando os custos e tempo gasto, além de elevar as chances de surgirem erros. Quando todas essas informações estão dentro de um único sistema, erros são mais difíceis de acontecer e o gerenciamento e análise de todas essas informações ficam mais rápidas e com custos menores. O software ERP serve para isso.

Fontes de pesquisa:
- http://www.scielo.br/pdf/%0D/gp/v9n3/14570.pdf
- http://www.anpad.org.br/admin/pdf/enanpad1999-ai-13.pdf
- http://www.race.nuca.ie.ufrj.br/teses/usp/Souza.pdf
- http://www.scielo.br/pdf/%0D/prod/v15n1/n1a08.pdf
ETL
Conceito e definição.
- ETL (sigla do inglês Extract, Transform and Load - Extrair, Transformar e Carregar) é uma forma de se integrar os dados que consiste em extrair os dados de diversas fontes operacionais, tratar esses dados de maneira consistente para serem consumidos pela equipe OLAP (Online Analytical Processing - ferramentas para elaboração de relatórios) e armazenar essas informações no banco de dados (em data warehouses, para o caso de bancos de dados relacionais ou datalakes para soluções Big Data).

- Extrair o dado é buscá-lo na origem operacional da sua aplicação/projeto. É importante que ele seja consumido da maneira mais pura possível para que, a partir de suas lógicas e padrões, na etapa seguinte você consiga imprimir uma qualidade neste dado.
- As ferramentas de extração do mercado conectam-se a um servidor de banco de dados (Ex.:Oracle) e recebe as informações das ferramentas operacionais e já o estrutura em forma de tabelas (arquivos flat) com um certo padrão específico (com chaves, ordenação, nomeação de campos etc)
- Transformar o dado é organizá-lo, tratá-lo para retirar suas imperfeições e deixá-lo da maneira mais coesa e simples possível para que relatórios confiáveis sejam elaborados a partir deste dado. Ele precisa fazer sentido e ser de fácil compreensão em sua leitura.
- Alguns passos da transformação do dado é a limpeza de imperfeições nos dados e padronização destes, corrigindo formatações erradas, agregando em métricas e indicadores importantes para que as ferramentas visuais OLAP tenham a melhor performance possível.
- Carregar o dado por sua vez consiste em armazená-lo em um bancos de dados de sua escolha. Hoje as soluções são diversas devido as diferentes necessidades de bancos de dados do mercado.
- Dentre as soluções atuais para armazenamento, temos o Big Data em termos não-relacionais ou o Data Warehouse tradicional em seu modelo relacional.
- Referências
eXtreme Programming
- O que é o XP - eXtreme Programming?
- O eXtreme Programming é uma método ágil de desenvolvimento de software que traz melhor qualidade, menor tempo de desenvolvimento e menores custos. Para a prática desse método devem ser seguidos um conjunto de valores: comunicação, coragem, feedback, respeito e simplicidade.
- Nessa prática o projeto vai sendo entregue ao cliente em pequenos pedaços conforme a sua necessidade, assim podendo ser modificado e melhorado de acordo com o que o mesmo precisa. Isso faz com que o projeto seja mais produtivo já que é organizado de forma simples e eficiente para que a equipe possa junta achar soluções para os problemas propostos.
- De acordo com os valores do XP, os programadores extremos devem sempre estar se comunicando tanto quanto com os outros programadores quanto com o próprio cliente, para do segundo receber o feedback dos testes diários que devem ser feitos. Mantendo o design sempre simples eles devem entregar o projeto ao cliente o mais cedo possível, respeitando as mudanças que cada parte da equipe sugerir e tendo coragem para enfrentar mudanças na codificação, nas tecnologias utilizadas, etc.

- Valores do XP:
- Comunicação: a comunicação é uma parte essencial para a resolução dos problemas propostos para o projeto já que o cliente que cria a demanda possui por si só ideias de como resolver o mesmo porém não tem a capacidade técnica de realiza-lo, para isso os programadores entre si e os clientes devem estar em constante contato para que assim as ideias fluam de melhor maneira e não há melhor forma de se comunicar do que com um diálogos presenciais, já que a partir deles você consegue absorver muito mais informações como gestos, sentimentos, emoções, tons de voz, que as vezes não podem ser captados por videoconferências, ou telefonemas, emails. Dessa forma a comunicação dentro de um projeto que usa essa metodologia deve ser através do dialogo para maior compreensão de ambas as partes.
- Coragem: a coragem se configura de forma que as equipes XP não veem mudanças no projeto como um atraso ou como algo negativo mas encaram essa como algo natural e inevitável, já que eles tem em mente que o próprio cliente tende a mudar suas ideias, suas necessidades e prioridades, portanto é necessário coragem para enfrentar esses tipos de mudança já que para realizá-las as vezes é necessário mudar tudo que se havia programado mesmo que estivesse funcionando perfeitamente.
- Feedback: programadores extremos têm em mente de que erros e problemas são propensos em projetos de software, além de que esses projetos são extremamente caros. Logo, para reduzir custos e tempo de desenvolvimento, eles entregam sempre o mais rápido possível partes pequenas do seu projeto para o cliente para que o mesmo possa avaliar e ver se está dentro do esperado, tentando estar o mais próximo possível de seus desenvolvedores para tirar quaisquer dúvidas que eles tiverem, sendo assim um feedback mútuo entre as duas partes, que dependem uma da outra.
- Respeito: o nome é autoexplicativo, é necessário respeito entre as partes desenvolvedoras do projeto pois só assim encontrarão melhores soluções em equipe, ouvindo uns aos outros e sabendo compreender o que cada um sugere.
- Simplicidade: esse valor se assemelha muito ao sistema de produção da Toyota, o Just In Time, que tem como característica produzir somente aquilo que for necessário, assim os desenvolvedores se atentam às necessidades atuais sem se preocupar com funcionalidades extras, já que nessa metodologia o foco é terminar algo simples agora e entregá-lo o mais rápido possível com certeza de que está funcionando e depois fazer modificações e implementações, pois assim ganham velocidade de produção e não entregam coisas desnecessárias ou não funcionais.

- O XP possui 12 práticas que se baseiam nos valores citados acima e levam em consideração que estas devem ser feitas de forma coletiva para diminuir possíveis erros e inconsistências, são elas:
- Planning Game: essa é a fase de planejamento do projeto, aonde o cliente e seus desenvolvedores sentam para discutir aspectos técnicos, datas, funcionalidades etc. Porém essa não é uma fase única, já que uma boa equipe XP fará essa etapa diariamente para buscar melhorias e defeitos no projeto inicial.
- Small Releases: se trata de desenvolver pequenas partes do projeto e entregá-las o mais rápido possível para que essas sejam gradualmente desenvolvidas, sem tentar antecipar tarefas na base da especulação, sempre aguardando o momento certo para as demandas e exigências.
- Metaphor: a utilização da metáfora é para melhorar a comunicação entre a equipe em si e com o cliente, criando assimilações de elementos físicos, do dia-a-dia, com os elementos do projeto.
- Simple Design: fazer o mais simples possível em todas as etapas do projeto. O código deve ser claro e objetivo, sem complexidades para que outros desenvolvedores possam continuar de onde o último terminou.
- Testing: os testes devem ser feitos diariamente de forma que tudo que for feito deve ser testado antes de passar para a próxima etapa do projeto para assim diminuir ao máximo as possíveis falhas.
- Refactoring: é a reestruturação do sistema de forma ininterrupta, modificando e implementando funcionalidades novas.
- Pair Programming: programação em dupla, ou seja, duas pessoas desenvolvendo o projeto em uma mesma máquina para assim melhorar a qualidade do código e a comunicação da equipe, sendo as duplas alteradas constantemente, de forma que cada um da dupla tenha experiência em uma área necessária.
- Collective Code OwnerShip: qualquer desenvolvedor da equipe pode modificar os códigos dos demais sem ter que pedir permissões, porém com os devidos testes de unidade.
- Continuos Integration: os módulos do software devem ser armazenados a cada etapa concluída em um repositório em que todos tenham acesso, após passarem por todos os testes necessários.
- 40 Hour Week: essa prática baseia-se em que cada um possui um ritmo, uma forma de trabalhar, uma intensidade, logo para reduzir desgastes físicos e psicológicos, que consequentemente afetam de forma negativa o software produzido, a equipe XP deve ter uma carga de 40 horas de trabalho semanal, podendo fazer horas extras, sem que estas sejam frequentes.
- On-site Customer: é a utilização de um usuário real do software na equipe, assim gerando feedbacks mais reais e rápidos do produto que ele está utilizando.
- Coding Standars: criação de um padrão para que outros desenvolvedores possam integrar ideias no código sem ter dificuldades no entendimento do mesmo, assim melhorando a comunicação da equipe, o que agiliza a criação do código e o deixa mais consistente.
- Referências:
- https://www.devmedia.com.br/introducao-ao-extreme-programming-xp/29249
- https://medium.com/@brunofeitosa/comece-a-usar-xp-extreme-programming-no-seu-time-%C3%A1gil-5664cf0da100
- http://www.extremeprogramming.org/
- http://www.desenvolvimentoagil.com.br/xp/
- http://redspark.io/metodologias-parte-2-xp-extreme-programming/
FDD
- Definição:
Feature Driven Development(FDD) é uma metodologia ágil de desenvolvimento de software. Esta metodologia permite desenvolver um sistema de forma rápida e permite facilmente introduzir novas features (funcionalidades) a este. Uma nova feature demora entre duas horas a duas semanas a ser concluída. O facto de no FDD usar-se processos simples proporciona uma rápida exposição do projecto a novos elementos que venham a fazer parte da equipa, assim como torna o trabalho menos monótono, uma vez que se esta sempre a iniciar/acabar um processo.
- Descrição dos processos:
A metodologia FDD consiste em cinco processos sequenciais. O uso de processos tem várias vantagens: O facto de nos FDD’s usarem processos simples e bem definidos faz com que o mover novas utilidades (features) para projectos grandes seja fácil. Pois é como fazer algo simples várias vezes. No desenvolvimento de processos complexos, deve-se dividir em N processos simples, o permite que o progresso do projecto seja mais rápido. - A integração de novos elementos nas equipas é rápida, pois o facto de os processos serem simples faz com que seja fácil a compreensão destes por parte dos novos membros. - O facto de os processos serem simples, faz com que a equipa esteja sempre concentrada no trabalho uma vez que estão constantemente a acabar/iniciar um novo processo. Não causa uma monotonia do trabalho.
- Como tinha sido referido acima esta metodologia consiste em cinco processos
sequenciais sendo estes:
1. Develop an Overall Model (Desenvolver um modelo geral) (Trata-se de utilizar os requisitos e funcionalidades pedidas pelo cliente e fazer o estudo destas de forma a fazer a estrutura do sistema. Baseia-se no desenho do sistema);
2. Build by Features list (Criar por lista de recursos)(Constrói uma lista de features detalhada e ordenada por ordem hierárquica);
3. Plan By Feature (Planejar por recurso)(Trata-se de planear como devem ser desenvolvidas as features);
4. Design by Feature (Design por recurso)(Analisa uma feature em particula r e estuda-a de forma a criar-se um detalhado diagrama sequencial, que será os passos a seguir para construir uma feature);
5. Build By Feature (Construir por recurso)(Faz todas as alterações necessárias para ser possível construir uma feature).
- Referências :Artigos acadêmicos sobre metodologias FDD's e metodologia ágil,nomeadamente:
https://paginas.fe.up.pt/~aaguiar/es/artigos%20finais/es_final_22.pdf
Firewall
Definição:
- Sistema de segurança que visa proteger uma rede local de ameaças de redes externas e de hosts na mesma rede.
- Analisa o tráfego de dados entre as redes baseado em suas “políticas de segurança”, selecionando, assim, os tipos de dados que devem ter a passagem permitida.
- Políticas de Segurança: lista de regras pré-definidas pelo desenvolvedor e administrador, com relação ao conteúdo que flui entre as redes.
- Todo dado que entra(incoming) e sai(outgoing) da rede é avaliado pelo firewall, assim, o que for considerado malicioso é barrado e o que for considerado aceitável é permitido.

- Existem diversos tipos de firewall, cada um desenvolvido para uma situação diferente, como o tipo do conteúdo a ser protegido, sistema operacional e vários outros fatores.
- Entre os principais estão:
- Filtro de Pacotes (packet filtering):
- Compara o conteúdo de cada pacote ip que passa pelo firewall com as políticas de segurança, podendo, assim, permitir o encaminhamento dos dados ou descarta-los.
- O pacote ip é comparado com cada regra da política de segurança em ordem até encontrar uma regra correspondente com o conteúdo, e, assim, uma ação previamente definida para aquela situação é aplicada e as regras subsequentes são ignoradas.
- Caso nenhuma regra correspondente seja encontrada é aplicado um procedimento padrão, como “Descartar(Drop/Block/Deny)” ou “Permitir(Allow)”.
- O filtro de pacotes analisa: IP de origem e destino, Número de portas de comunicação, Tipo de protocolo, Interface da rede, e outros.
- Filtro de Pacotes (packet filtering):

- Filtro de Estado de Sessão (Inspeção de Estado):
- Tem um desempenho considerado maior que o do filtro de dados.
- Analisa o status das conexões de rede ativas, determinando se ela é ou não confiável para permitir ou não a passagem de dados.
- Monitora as atividades das conexões e do tráfego de dados definindo padrões aceitáveis segundo as regras, assim, ele toma como base esses padrões para analisar os próximos fluxos de dados.
- Caso haja uma atividade anormal em relação aos padrões definidos o bloqueio é realizado.
- Filtro de Estado de Sessão (Inspeção de Estado):
- Referências Bibliográficas:
Firmware
- Conceito
O Firmware e um software de computador que vem junto com Hardware. Ele serve para controlar as configurações do Hardware especifico do dispositivo, funções de controle, monitoramento e manipulação de dados. O software do está presente dentro de um microchip instalado dentro Hardware do dispositivo. Sistemas que possuem firmware podem ser encontrados em:
- Semáforos
- Aparelhos Celulares
- Bios, UEFI e EFI
- Placas de vídeos
- Referência bibliográficas
Frameworks
- Conceito
- Segundo Buschmann (1966), Pree (1995) e Pinto (2000) um framework é definido como um software parcialmnte completo projetado para ser instanciado. O framework define uma arquitetura para uma família de subsistemas e oferece construtores básicos para criá-los. Também são explicitados os lugares ou pontos de extensão (hot-spots) nos quais adaptações do código para um funcionamento específico de certos módulos devem ser feitas. Em síntese o framework é um conjunto de classes que colaboram entre si proporcionando melhores práticas de desenvolvimento e diminuição à repetição de tarefas. Além disso, evita variações de “soluções diferentes para um mesmo tipo de problema”. O que facilita a reutilização e customização dos códigos.
- Classificação de frameworks
- Framewoks podem ser classificados de diversas formas. Inicialmente, são classificados em dois grupos principais: frameworks de aplicação orientado a objetos (Fayad et al., 1999a, b; Fayad & Johnson, 2000) e framework de componentes (szyperski, 1997).
- Benefícios decorrentes da utilização de frameworks
- Os principais benefícios decorrentes da utilização de frameworks, segundo Fayad et al. (1999b) e Pinto (2000) advêm da modularidade, reusabilidade, extensibilidade e inversão de controle que os frameworks proporcionam. Framewoks encapsulam detalhes de implementação voláteis através de seus pontos de extensão, interfaces estáveis e bem definidas, aumentando a modularidade da aplicação. Os locais de mudanças de projeto e implementação da aplicação construída usando o framework são localizados, diminuindo o esforço para entender e manter a aplicação.
- Além disso, frameworks incentivam o reuso, pois capturam o conhecimento de desenvolvedores de determinado domínio ou aspecto de infra-estrutura ou de integração de middleware. As interfaces do framework promovem pontos de extensão que as aplicações estendem gerando instâncias que compartilham as funcionalidades no framework. Desta forma, aumentam a produtividade dos desenvolvedores, pois o processo não começa do zero, a qualidade e a confiabilidade do produto final, pois idealmente as funcionalidades do framework já foram testadas em diversas instâncias, e a interoperabilidade de software, pois as instâncias de uma mesma família compartilham características em comum.
- Frameworks oferecem pontos de extensão explícitos que possibilitam aos desenvolvedores estenderem suas funcionalidades para geram uma aplicação. Os pontos de extensão desacoplam as interfaces estáveis do framework e o comportamento de um determinado domínio de aplicação das variações requeridas por uma determinado aplicação em um dado contexto.
- Por fim, alguns frameworks apresentam inversão de controle (Inversion of Controll - IoC). Inversão de controle, também é conhecida como princípio de Hollywood : "Don't call us, we will call you" (Larman, 2004). Trata-se de transferir o controle da execução da aplicação para o framework, que chama a aplicação em determinados momentos como na ocorrência de um evento. Através da IoC o framework controla quais métodos da aplicação e em que contexto eles serão chamados em decorrência de eventos, como eventos de janela, um pacote, enviado para uma determinada porta, entre outros.
- Desafios decorrentes da utilização de frameworks
- Quando usado em conjunto com padrões de projetos, bibliotecas de classes, componentes, entre outros, frameworks de aplicação têm o potencial para aumentar a qualidade de software e reduzir o esforço de desenvolvimento. Contudo, instituições que tentam construir ou usar frameworks frequentemente falham a menos que resolvam os seguintes desafios: esforço de desenvolvimento, curva de aprendizagem, integração, eficiência, manutenção, validação e remoção de defeitos e falta de padrões ( Fayad et al., 1999b).
- Destes desafios, o esforço de desenvolvimento afeta principalmente os projetistas de frameworks. A curva de aprendizagem, a integração e a eficiência
afetam principalmente os desenvolvedores de aplicação. A manutenção e validação e remoção de defeitos afetam tanto desenvolvedores de aplicação quanto mantenedores de frameworks e a falta de padrões afetam a todos envolvidos no desenvolvimento e uso dos frameworks.
- O desafio do esforço de desenvolvimento ocorre devido à alta complexidade envolvida no projeto de um framework. Se desenvolver aplicações complexas é difícil, desenvolver frameworks que sejam de alta qualidade, extensíveis e reusáveis para domínios de aplicações complexos ou para tratar aspectos de infra-estrutura ou de integração de middleware é ainda mais difícil. Projetistas de frameworks devem estar cientes dos custos decorrentes do desenvolvimento de frameworks de aplicação.
- Quanto à curva de aprendizagem, aprender a usar um framework de aplicação leva tempo e incorre em custos. A menos que o esforço de aprendizado possa ser amortizado através do uso do framework em muitos projetos, ou em projetos duradouros, o investimento pode não compensar. Deve ser analisado se os benefícios trazidos pelo framework compensam os custos com o treinamento da equipe de desenvolvimento.
- O desafio da integração ocorre quando diversos frameworks são usados com outras tecnologias e com sistemas legados não previstos pela arquitetura do framework. Antes de usar um framework o desenvolvedor de aplicações deve analisar possíveis problemas que possam surgir ao incorporar novos frameworks à aplicação.
- Além disso, aplicações usando frameworks podem apresentar desempenho inferior a aplicações específicas. Para tornarem-se extensíveis, frameworks de aplicações adicionam níveis de indireção. Aplicações genéricas tendem a obter desempenho inferior a aplicações específicas (Fayad et al., 1999b). Desta forma o desenvolvedor de aplicações deve considerar se os ganhos advindos do reuso compensam uma potencial perda de desempenho.
- Frameworks inevitavelmente precisam ser mantidos. A manutenção em frameworks toma diversas formas como, correção de erros de programação, acréscimo ou remoção de funcionalidades, acréscimos ou remoção de pontos de extensão, etc. A manutenção é realizada pelos mantenedores do framework, que precisam ter um conhecimento profundo sobre os componentes internos e suas interdependências. Em alguns casos, a própria instância do framework sofre manutenção para acompanhar a evolução do framework. Cabe ao desenvolvedor da aplicação considerar o esforço de manutenção gasto para obter os benefícios de uma nova versão do framework.
- Além disso, a validação e remoção de erros de um framework ou de uma aplicação que usa um framework é um desafio, pois o framework é uma aplicação inacabada, o que torna difícil tanto para os mantenedores de frameworks quando para os desenvolvedores de aplicação testar, respectivamente, o framework e a instância do framework isoladamente. Aplicações que usam framework costumam ser mais difíceis de depurar, pois devido a IoC, o controle da execução oscila entre a aplicação e o framework.
- Por fim, ainda não há um padrão amplamente aceito para desenvolver, documentar, implementar e adaptar frameworks. Todos os papéis envolvidos no desenvolvimento e uso do framework são afetados por este desafio, sendo que os mais afetados são os mantenedores do framework e o desenvolvedor de
aplicações. O primeiro, pois precisa ter um conhecimento profundo sobre os componentes internos e suas interdependências. O segundo, pois a falta de um padrão de documentação de frameworks dificulta o seu uso.

- Referências bibliográficas
http://revistapensar.com.br/tecnologia/pasta_upload/artigos/a95.pdf
https://www.maxwell.vrac.puc-rio.br/8623/8623_3.PDF
IA
- Conceito
A inteligência artificial é uma tecnologia analisada a décadas, tendo parte de seu conceito deturpado por obras de ficção. Entretanto, o verdadeiro conceito da IA é simples: pensar, decidir e solucionar problemas de maneira independente e racional, assim como um humano, mas tendo um acesso infinitamente maior à dados de apoio. A IA tem presença constante em cada momento do cotidiano da civilização contemporânea, como no corretor ortográfico do celular, onde a medida que o usuário insere informações, a máquina "aprende" com esses dados e entende as sugestões de correção mais adequadas nas frases. Atualmente, o conceito mais comum de IA que temos no dia a dia é a IA Fraca, que é uma inteligência artificial direta, focada em um número limitado ou em uma única função e usando dados relacionados apenas a ela. Exemplos da IA Fraca podem ser observados em:
- Reconhecimento Facial
- Corretor ortográfico
- Sugestão em pesquisas na internet
Porém, o objetivo a longo prazo é desenvolver uma IA Forte, ou IA Geral. Enquanto a IA Fraca supera a capacidade humana em uma tarefa específica, a IA Forte pode fazer isso em todas as atividades que um humano pode realizar.
- Definições dentro de IA
Inteligência Artificial não é algo único, mas sim uma tecnologia feita da conexão de 3 conceitos principais:
- Machine Learning:
- Em vez de programar regras para uma máquina e esperar o resultado, conseguimos deixar que a máquina aprenda essas regras por conta própria a partir dos dados, chegando ao resultado de forma autônoma. As recomendações personalizadas na Netflix e na Amazon, por exemplo, indicam os títulos de acordo com o que o usuário assiste. Conforme você inclui dados (assiste) o sistema aprende os gostos do cliente.
- Deep Learning:
- É a parte do aprendizado da máquina que utiliza algoritmos complexos para “imitar a rede neural do cérebro humano” e aprender uma área do conhecimento com pouco ou sem supervisão. Por exemplo, um sistema pode aprender como se defender de ataques sozinho.
- Processamento de Linguagem Natural:
- Esse processamento utiliza as técnicas de machine learning para encontrar padrões em grandes conjuntos de dados puros e reconhecer a linguagem natural. Assim, um dos exemplos de aplicação é a análise de sentimentos, onde os algoritmos podem procurar padrões em postagens de redes sociais para compreender como os clientes se sentem em relação a marcas e produtos específicos.
- Importância da IA
A IA automatiza a aprendizagem repetitiva e a descoberta a partir dos dados. Mas a inteligência artificial é diferente da automação robótica guiada por hardwares. Em vez de automatizar tarefas manuais, a IA realiza tarefas frequentes, volumosas e computadorizadas de modo confiável. Para este tipo de automação, a interferência humana ainda é essencial na configuração do sistema e para fazer as perguntas certas.
A IA adiciona inteligência aos diversos produtos e serviços utilizados pela população. Um exemplo que está em alta hoje em dia são os chatbots, avatares virtuais de lojas ou aplicativos que funcionam como um "atendimento ao cliente". Ao ser aprimorada com cada vez mais dados de diversos usuários, a IA aprende com eles, aprimorando-se. Nota-se assim, uma adaptação da máquina, que com a entrada constante de dados, ela é capaz de ensinar a si como realizar uma atividade, seja ela dirigir um carro ou recomendar um filme.
Além da sua função na área de entretenimento, a Inteligência artificial pode tomar um rumo para a segurança pública, como detecção de fraudes ou o reconhecimento facial de pessoas suspeitas de terem cometido um crime, usando da técnica de Deep Learning. Ela pode também ser utilizada na área médica, para reconhecer sintomas e até mesmo encontrar cânceres em ressonâncias.
Em suma, cada aspecto do cotidiano pode ter a utilização e terá benefícios com a inteligência arfiticial, desde o lazer, até a área de saúde, segurança, esportes ou comércio, auxiliando as tarefas manuais exercidas pelos humanos ou por máquinas inferiores, visando sempre recolher o máximo de dados possíveis para obter os melhores resultados.
- Desafios do uso de IA
O principal limite da inteligência artificial são os dados. Não há outra maneira do conhecimento ser passado à máquina sem eles, logo, caso estejam incorretos, os resultados serão comprometidos. Sendo assim, camadas independentes para prever esses erros devem ser adicionadas uma a uma. Como citado anteriormente, atualmente temos apenas IA's Fracas, sendo assim, uma IA que joga xadrez não pode fazer correções ortográficas. Uma IA que detecta fraudes não pode dirigir um carro. Portanto, elas são focadas em tarefas independentes e são incapazes de levar em conta todo o comportamento humano. Entretanto, existem dois cenários considerados mais comuns pelos pesquisadores ao analisar os rumos em que a IA assuma um risco:
- Uma IA que seja programada com intúitos de causar dano, como o de armas autônomas. Nas mãos erradas, pode ter resultados devastadores à vida humana.
- Uma IA programada para fazer algo benéfico, mas que desenvolve uma maneira caótica de alcançar seu objetivo. Ao falhar na programação do sistema para alinhar o raciocínio do programador e o da máquina, ela pode interpretar os dados sem analisar o "caminho" percorrido para chegar até ele. Por exemplo, ao pedir que um carro que dirige sozinho o leve até algum lugar, ele pode cometer diversas infrações de trânsito e/ou crimes para alcançar o seu destino, interpretando que o que ele fez foi correto, já que não fora programado corretamente.
- Como programar uma IA
Existem diversas bibliotecas com algoritmos e recursos já prontos, como:
- OpenCV, uma biblioteca open source de funções de programação voltadas especificamente para visão computacional. De maneira resumida, ela facilita o processo de permitir que os sistemas “entendam” imagens. O OpenCV é usado em casos que necessitam desse tipo de capacidade de interpretação de imagens.
- SciKit, que contém uma série de recursos de código aberto voltados para machine learning. Trata-se de uma biblioteca que também é usada por empresas como Spotify, Evernote, Change.org e OkCupid.
- KERAS, uma biblioteca open source de redes neurais, criada especificamente para permitir a realização de experimentos rápidos com redes neurais profundas. Resumidamente, ele facilita o processo de implementar e testar redes mais complexas.
Todas essas ferramentas têm em comum o suporte a Python, que é uma linguagem de programação que facilita o processo de rodar experimentos e provas de conceito rapidamente.
- Referências Bibliográficas
- https://futureoflife.org/background/benefits-risks-of-artificial-intelligence/?cn-reloaded=1
- https://www.sas.com/en_us/insights/analytics/what-is-artificial-intelligence.html
- https://canaltech.com.br/inteligencia-artificial/entenda-a-importancia-da-inteligencia-artificial-100442/
- https://cryptoid.com.br/inteligencia-artificial/como-programar-uma-ia-inteligencia-artificial/
- https://tecnoblog.net/263808/o-que-e-inteligencia-artificial/
IDE
Conceito
- IDE, ou Ambiente Integral de Desenvolvimento em tradução livre, é um software criado com a finalidade de facilitar a vida dos programadores. Neste tipo de aplicação estão todas as funções necessárias para o desenvolvimento desde programas de computador a aplicativos mobile, assim como alguns recursos que diminuem a ocorrência de erros nas linhas de código. Se no passado os desenvolvedores precisavam apenas de um editor de texto e de um navegador para criar um software, agora, com os IDEs, eles possuem mais opções para otimizar o tempo gasto com os códigos. Imagine os IDEs como as calculadoras. Logicamente você aprende a fazer as operações matemáticas na escola, mas raramente as faz manualmente quando precisa.
Vantagens
- Possibilita verificação de erros
- Diminui gastos
- Diminui tempo de produção
- Aumenta desempenho
- Aumenta produtividade
- Mais opções para otimizar o tempo gasto com os códigos
Desvantagens
- A desvantagem fica por conta de necessitar um conhecimento razoável de programação. Usuários com pouca experiência – ou que estão dando os primeiros passos no desenvolvimento de software – podem se confundir com o excesso de recursos que alguns IDEs têm. Porém, isso não se mostra um grande problema.
Referências Bibliográficas
Integração Contínua
- Conceito
- Integração contínua (continuous integration) é um termo originado na metodologia ágil XP que refere a uma prática de desenvolvimento de software de DevOps para que os desenvolvedores, com frequência, juntem suas alterações de código em um Servidor central, que visa tornar a integração de código mais eficiente, através de builds e testes automatizados.
- Para que?
- No passado, os desenvolvedores de uma equipe podiam trabalhar isoladamente por um longo período e só juntar suas alterações à ramificação mestre quando concluíssem seu trabalho, que consequentemente poderia havia muito acumulo de erros sem correção por um longo período, logo objetivo principal é de facilitar e agilizar as junções dos código. Utilizando a integração contínua é possivel verificar se as alterações ou novas funcionalidades não criaram novos defeitos no projeto já existente assim podendo lançar atualizações para atender as demandas dos usuários com maior frequência.

- Controle de versão
- Como parte crucial no processo de desenvolvimento e, para o sucesso da integração contínua, o controle de versão deve ser utilizado. Sendo que um dos objetivos do controle de versão é o trabalho colaborativo, em que diversos desenvolvedores trabalham em conjunto e compartilhando dados.
- O sistema de controle de versão resolve um grande problema quando trabalhamos em equipe:
- como compartilhar as informações de forma a ter a última versão válida e ainda saber quem fez as alterações;
- como prevenir que os desenvolvedores refaçam o trabalho já desenvolvido, etc.
- Para solucionar estes problemas, existe um conjunto de ferramentas para controle de versão centralizado, entre elas temos o CVS, Subversion, Git, entre outros. Estas ferramentas permitem aos desenvolvedores trabalharem em conjunto, possuindo um Servidor central responsável pelo versionamento do sistema e possibilitando que vários clientes possam acessar, visualizar, modificar e enviar novos códigos se for necessário.
- Ferramentas para Integração contínua
- As ferramentas de integração contínua permite que seja configurado o seu sistema, o ambiente de desenvolvimento (exemplo: jdk), permite que seja configurado o sistema de build automatizado como o ant, integrar com o repositório de controle de versão, e permite ainda o envio de e-mails de notificação. Isto é importante, pois como o sistema é automatizado, caso ocorram erros, o desenvolvedor pode ser notificado que a integração gerou falhas, para poder ser analisada. Existem diversas ferramentas, entre elas o, Hudson, Jenkins, Travis, Cruise Control entre outros.
- Fontes de pesquisa
Inteligência Cognitiva
- Como entender?
- As informações manipuladas pelos seres humanos podem existir através de ideias ou valores. É por causa da inteligência cognitiva que conseguimos discernir as relações entre os dados concretos e abstratos da nossa mente, por exemplo.
- - A cognição se trata da aquisição de conhecimento através da “percepção, atenção, associação, memória, raciocínio, juízo, imaginação, pensamento e linguagem”. E o estudo do pensamento cognitivo visa ajustar o ser humano para que possa raciocinar agregando todos estes aspectos.
- - Desta forma, o aprendizado é contínuo e sempre em sintonia com as mudanças ao redor, permitindo com que cada pessoa possa evoluir, acompanhando seu entorno.
Existem duas formas de atividade para a inteligência cognitiva: a criativa e a reprodutiva. Na primeira, criamos condições e situações nas quais a experiência é inexistente.
- - Já na segunda acontece um processo de identificação e reprodução das condições e situações já estabelecidas por um ambiente anterior. O interessante é que não existe uma época errada para desenvolver a inteligência cognitiva. Ela pode receber atenção em qualquer momento da vida, desde a infância até a velhice. De fato, ela acontece até de maneira natural.
- - Na primeira infância, por exemplo, quem se perguntar o que é inteligência cognitiva vai identificá-la no processo natural de aprendizagem da fala, do andar e de outros aspectos naturais da vida humana.
- - Nos seres humanos, a inteligência cognitiva vem sendo uma área do conhecimento explorada de forma contundente, a muito tempo. O aprimoramento das habilidades cognitivas de um ser humano permite a ele agregar diversos conhecimentos, de diferentes áreas, para executar uma função. Algo que as máquinas até então não eram capazes de aprender.

- Como funciona a inteligência cognitiva na tecnologia?
- - Quando falamos de inteligência cognitiva na tecnologia, estamos inevitavelmente nos referindo à inteligência artificial. Mas, como ela funciona?
A inteligência cognitiva na tecnologia é capaz de aprender com base em dados uma das matérias-primas inovação, aplicando modelos estatísticos para entender padrões de ocorrências ao longo de determinado período.
- - Um sistema cognitivo competente ainda pode gerar um raciocínio acessando enormes quantidades de dados, imitando a maneira como o cérebro humano funciona.
- - O desenvolvimento da inteligência artificial diz respeito também a uma maior compreensão acerca da inteligência cognitiva para as máquinas. Hoje, existem diferentes tipos de softwares capazes de atuar nas áreas de economia, saúde, finanças, entretenimento e varejo, por exemplo.
Internet
- O que é Internet?
- A internet é o conjunto de redes de computadores e outros dispositivos que, espalhados por todas as regiões do planeta, conseguem trocar dados e mensagens utilizando um protocolo comum. Este protocolo compartilhado pela internet é capaz de unir vários usuários particulares, entidades de pesquisa, órgãos culturais, institutos militares, bibliotecas e empresas de todos os tipos em um mesmo acesso.

- Como ela funciona?
- Quando conectamos um computador a outro, ou quando ligamos vários computadores uns aos outros, criamos uma rede local. Mas desta forma, os computadores só se comunicam uns com os outros, sem acesso a outros computadores fora da sua casa ou empresa, sem acesso a outros servidores, como é possível quando há acesso à Internet.
- Este acesso externo ocorre quando a sua rede local se conecta a uma outra rede maior - no caso, o seu provedor de Internet - por meio da tecnologia TCP/IP, um modo de comunicação baseado no endereço de IP (Internet Protocol). Este IP é o endereço de cada um dos pontos de uma rede, e cada ponto da rede consiste em um computador que, por sua vez, se interliga a outros computadores, formando uma verdadeira “teia de redes”.
- Meios de conexão:
- Conexão Dial-up: É um tipo de conexão por linha comutada ou dial up, no qual é necessária a utilização de um modem e de uma linha telefônica para se conectar a um dos nós de uma rede de computadores do provedor de Internet
- A banda larga (em cabos coaxiais, fibras ópticas ou cabos metálicos): O termo banda larga pode apresentar diferentes significados em diferentes contextos. define –se banda larga como a capacidade de transmissão que é superior àquela da primária do ISDN a 1.5 ou 2 Megabits por segundo.
- Wi-fi: O padrão Wi-Fi opera em faixas de frequências que não necessitam de licença para instalação e/ou operação.
- Satélites: Internet via satélite é um método de acesso à Internet que, na teoria, pode ser oferecido em qualquer parte do planeta. Possibilita altas taxas de transferências de dados
- Telefones celulares : As tecnologias presentes em celulares permitem às operadoras da rede oferecerem aos seus usuários uma ampla gama dos mais avançados serviços, já que possuem uma capacidade de rede maior por causa de uma melhora na eficiência espectral.
- Sua impotância para a sociedade:
- Atualmente a Internet é o mais usado meio de comunicação, pois a partir dela surgem outros meios como aplicativos de mensagens e ligações. A cada dia que passa mais ela esta presente nos diversos setores existentes, como o comercial facilitando a comunicação entre vendedor/cliente.No campo educacional , é nela onde se encontra várias informações que ajudam o desenvolver dos estudantes . Ou seja , quase todos os setores envolvem seu uso sendo a principal ferramenta mundial.

- Referências bibliográficas:
IoT
- Conceito
O conceito de IoT (Internet of Things) ou em português Internet das Coisas, pode ser definido como uma enorme rede de dispositivos conectados. Sensores são embutidos nesses dispositivos, que engloba diversos objetos do dia-a-dia, como geladeira, máquina de lavar, termostato, alarme de incêndio, sistema de som, lâmpadas, entre outros, afim de coletar dados e tomar decisões baseadas nesses dados em uma rede.
A ideia é que essa conectividade torne a vida mais confortável, produtiva e prática. Nesse sentido, uma geladeira com internet pode avisar quando um alimento está perto de acabar e, ao mesmo tempo, pesquisar na web quais mercados oferecem os melhores preços para aquele item. A geladeira também poderia pesquisar e exibir receitas para você.

- Importância e uso real
A Internet das Coisas é mais do que apenas uma conveniência para os consumidores. Ela oferece novas fontes de dados e modelos de operação de negócios que podem aumentar a produtividade de diversas indústrias.
Alguns exemplos:
- Saúde: pode ajudar no monitoramento de atividades físicas, sono e outros hábitos – e esses itens estão apenas arranhando a superfície do quanto a IoT pode impactar a área da saúde. Aparelhos de monitoramento de batimentos cardíacos ou pressão sanguínea, registros eletrônicos e outros acessórios inteligentes podem ajudar a salvar vidas.
- Agropecuária: sensores espalhados em plantações podem dar informações bastante precisas sobre temperatura, umidade do solo, probabilidade de chuvas, velocidade do vento e outras informações essenciais para o bom rendimento do plantio.
- Manufatura: uma das indústrias que mais se beneficiam da Internet das Coisas. Sensores embutidos em equipamentos industriais ou prateleiras de armazéns podem comunicar problemas ou rastrear recursos em tempo real, aumentando a eficiência do trabalho e reduzindo custos.
Em geral, se um objeto é um eletrônico, ele tem potencial para ser integrado à Internet das Coisas. Assim, não é difícil de perceber por que esse assusto tem sido tão comentado atualmente.
De forma a ilustrar melhor o impacto da IoT, vamos usar um exemplo do nosso dia-a-dia. Vamos dizer, por exemplo, que você tem uma reunião de manhã cedo; seu despertador, conectado com o seu calendário, te acorda na hora certa. As luzes do seu quarto se acendem, a cortina abre automaticamente. Antes disso, sua cafeteira já começou a fazer o café, e a torradeira começa a esquentar o seu pão. Quando você entra no carro, a sua música favorita começa a tocar. Seu carro também pode ter acesso ao seu calendário e contatos, e automaticamente saberá a melhor rota a ser tomada para atingir seu destino. Se estiver muito trânsito, seu carro enviará uma mensagem aos envolvidos, notificando eles de seu possível atraso.
Dentro do carro, você poderá ir lendo ou dormindo mais um pouco, pois ele também faz parta da Internet das Coisas, e como um veículo autônomo, pode dirigir sozinho de forma segura, comunicando-se com outros carros e com a infraestrutura da cidade.
Quando os objetos passam a antecipar as nossas necessidades, as tarefas rotineiras do dia-a-dia serão otimizadas.
- Possíveis riscos:
A maior preocupação é em relação à segurança e privacidade dos sensores usados em IoT e dos dados que eles armazenam. E mais do que isso, a integração de dispositivos para transferir todos os dados críticos também apresenta problemas.
Segundo o The CommLaw Group, entre junho e novembro de 2016, mais de 100 milhões de dispositivos relacionados à Internet das Coisas foram afetados por malwares em todo o mundo. Não se trata apenas de perder dados ou de tê-los comprometidos, mas de que essas pessoas acessem áreas fundamentais para a companhia, afetando serviços como até mesmo a energia elétrica. Os ataques de hackers têm um custo alto para boa parte das empresas: estima-se algo em torno de US$ 280 bilhões ao ano.
A indústria precisa, portanto, definir e seguir critérios que garantam disponibilidade dos serviços (incluindo aqui a rápida recuperação em casos de falhas ou ataques), proteção de comunicações (que, nas aplicações corporativas, deve incluir protocolos rígidos e processos de auditoria), definição de normas para privacidade, confidencialidade de dados (ninguém pode ter acesso a dados sem a devida autorização), integridade (assegurar que os dados não serão indevidamente modificados), entre outros.
- Referências bibliográficas:
IP
- O que é?
IP é uma sigla para Internet Protocol, ou Protocolo de Internet. O endereço de IP é uma sequência numérica que indica o local de onde um determinado equipamento (normalmente um computador) está conectado a uma rede privada, diretamente à Internet, ou o endereço do servidor pelo qual o dispositivo está se conectando à internet.
Toda a internet é baseada em endereços IP, e cada participante da rede mundial de computadores tem um endereço IP. Até mesmo sites tem endereços IP, ou seja, o lugar de onde estão vindo os dados daquele site específico.
Em uma mesma rede, jamais podem existir 2 dispositivos com o mesmo endereço IP. O endereço IP deve ser único de forma a distinguir entre quaisquer equipamentos de uma mesma rede. É uma forma de garantir também a segurança de todos.
- Como Funciona?
Para que seja encontrado, o seu computador precisa ter um endereço único. O mesmo vale para qualquer site, como o SourceInnovation: este fica hospedado em um servidor, que por sua vez precisa ter um endereço para ser localizado na internet. Isso é feito via endereço IP (IP Address), recurso também utilizado para redes locais, como a rede Wi-Fi da sua casa: o seu roteador atribui um IP a cada dispositivo conectado a ele.
O endereço IP é uma sequência de números composta por 32 bits. Esse valor consiste em um conjunto de quatro sequências de 8 bits. Cada uma é separada por um ponto e recebe o nome de octeto ou simplesmente byte, pois um byte é formado por 8 bits. O número 172.31.110.10 é um exemplo.

A divisão de um IP em quatro partes facilita a organização da rede, da mesma forma que a divisão do seu endereço em cidade, bairro, CEP, número, etc, torna possível a organização das casas da região onde você mora.
- Referências
IPSec
- Conceito
- Protocolo de Segurança IP (IPsec) é uma extensão do protocolo IP que visa a ser o método padrão para o fornecimento de privacidade do usuário (aumentando a confiabilidade das informações fornecidas pelo usuário para uma localidade da internet, como bancos), integridade dos dados (garantindo que o conteúdo que chegou ao seu destino seja o mesmo da origem) e autenticidade das informações ou prevenção de identity spoofing (garantia de que uma pessoa é quem diz ser), quando se transferem informações através de redes IP pela internet.O IPSec pode ser definido como uma plataforma formada por um conjunto de protocolos que fornecem os seguintes serviços de segurança:
- Controle de acesso;
- Integridade dos dados (pacotes);
- Autenticação do host origem;
- Privacidade nos dados (pacotes);
- Privacidade no fluxo dos dados (pacotes);
- Reenvio de pacotes;
- Protocolo de Segurança IP (IPsec) é uma extensão do protocolo IP que visa a ser o método padrão para o fornecimento de privacidade do usuário (aumentando a confiabilidade das informações fornecidas pelo usuário para uma localidade da internet, como bancos), integridade dos dados (garantindo que o conteúdo que chegou ao seu destino seja o mesmo da origem) e autenticidade das informações ou prevenção de identity spoofing (garantia de que uma pessoa é quem diz ser), quando se transferem informações através de redes IP pela internet.O IPSec pode ser definido como uma plataforma formada por um conjunto de protocolos que fornecem os seguintes serviços de segurança:
- Funcionamento
- O IPSec trabalha em dois modos, modo de Transporte e modo Túnel:
- Modo Transporte:
- No modo de Transporte, apenas o segmento da camada de transporte á processado, isto é, autenticado e criptografado. Este modo é aplicável para implementações em servidores e gateways, protegendo camadas superiores de protocolos, além de cabeçalhos IP selecionados. O cabeçalho AH é inserido após o cabeçalho IP e antes do protocolo de camada superior (TCP, UDP, ICMP), ou antes de outros cabeçalhos que o IPSec tenha inserido. Os endereços de IP de origem e destinos ainda estão abertos para modificação, caso os pacotes sejam interceptados.
- Modo Transporte:
- O IPSec trabalha em dois modos, modo de Transporte e modo Túnel:
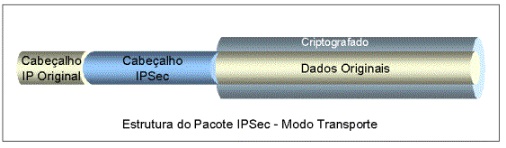
- Modo Tunel:
- No modo Túnel todo o pacote IP é autenticado ou criptografado, ficando apenas o cabeçalho IP externos (como o último endereço de destino e origem) visível, informando o destino do gateway (roteador, firewall, etc), permanecendo todo o conteúdo interno criptografado.Este método pode ser usado para evitar a análise de tráfego. Devido ao fato de o cabeçalho IP conter o endereço de destino e possivelmente as diretivas de roteamento e informação proveniente da opção hop-by-hop, não é possível simplesmente transmitir o pacote IP criptografado utilizando prefixo de cabeçalho ESP, pois roteadores intermediários seriam incapazes de processar tal pacote.Desta forma, é necessário encapsular o bloco inteiro (cabeçalho ESP mais pacote IP criptografado) com um novo cabeçalho IP que deverá conter informações suficientes para roteamento, mas não para análise de tráfego. Enquanto o modo de transporte é adequado para proteger conexões entre estações que suportam o modo ESP o modo túnel é útil numa configuração que inclua um firewall ou outro tipo de gateway de segurança que protege uma rede confiável das redes externas. No segundo caso, a criptografia acorre apenas entre uma estação externa e o gateway de segurança, ou entre dois gateways de segurança. Isto libera as estações da rede interna do processamento de criptografia e também simplifica a tarefa de distribuição de chaves pela redução do número de chaves necessárias. Além disso, inibe a análise de tráfego baseada no destino final.
- Modo Tunel:


- Vantagens
- Teremos uma grande proteção ataques feitos à uma rede, seja privada ou não. Obtem-se com ele uma interessante política de proteção à captura de dados. O IPSec não é de complexa configuração.Utilizamos sistemas de criptografia e protocolos de segurança, que são os grandes diferencias e que torna o IPSec tão atrativo quando falamos em uma conexão segura.Apenas os Hosts destino e origem deve “conversar” IPSec, todos os hops da rede apenas encaminharão o pacote IP ao seu destino.
- Bibliografia
Linguagens de Programação
Linguagem de programação, como fiz o nome, é uma linguagem usada para programar. Mas o que isso quer dizer? Quer dizer que, é uma maneira da qual nós humanos conseguimos "conversar" com dispositivos, podendo ser computadores ou até mesmo uma televisão. Esta conversa ocorre por meio de uma série de instruções e regras, que são usados para gerar softwares; tais softwares são quem fazem o intermédio desta conversa entre os programadores e os hardwares, as peças dos dispositivos.
Assim como ocorre no mundo, existem diversas linguagens de programação, dentre elas existem os tipos de linguagens:
- Programação estruturada: Uma forma de programar baseada em uma tríade: sequência, decisão e repetição. Exemplo de linguagem: Haskell.
- Programação Modular: No desenvolvimento das rotinas de programação, tal ação é feita por meio de módulos. Exemplo de linguagem: Modula-2
- Programação orientada a objetos: Programação, que seu principal paradigma é a orientação a objeto. Atualmente, 90% das linguagens tem suporte a este recurso.

- As linguagens também são classificadas em níveis (alto ou baixo). Existem aquelas em que a sintaxe se aproxima a uma linguagem humana, por isso entram na categoria das linguagens de alto nível. E também, existem as linguagens que possuem sintaxe e semântica próximas ao código de máquina, portando, classificadas como linguagens de baixo nível.
- Exemplo de linguagem de baixo nível: Assembly

- Exemplo de linguagem de alto nível: C

- Aqui segue uma tabela que mostra o TOP 20 linguagens de programação no mês de abril de 2019, comparado com o mesmo mês do ano de 2018, segundo o Tiobe Index.


- Logo abaixo, um TOP 10 das linguagens que mais se destacaram nos respectivos anos.

- Referências:
- https://www.tiobe.com/tiobe-index/
- SEBESTA, Robert W. Conceitos de Linguagens de Programação - 11.ed. [S. l.]: Bookman Editora, 2018. Disponível em: book.google.com.br. Acesso em: 15 abr. 2019.
- https://universidadedatecnologia.com.br/o-que-e-linguagem-de-programacao/
Machine Learning
- O que é?
- Uma ramificação da área de Inteligência Artificial, enquanto essa se baseia em “imitar” atitudes humanas, a Machine Learning em si, como o nome sugere, é o procedimento em que a máquina realmente aprende, por meio de análise de dados e identificação de padrões, a tomar decisões teoricamente conscientes, com o mínimo possível de intervenção humana.
- Desde muito tempo atrás, os computadores não eram capazes de realizar nada mais, nada menos do que o que fora programado para fazer, mas por que tratar as máquinas somente como máquinas? Logo no começo de tal estudo, pesquisadores focados em IA demandaram tempo e trabalho submetendo testes de reconhecimento de padrões, visando saber se os computadores realmente poderiam aprender – independentemente – quando expostos a novos dados.
- Por quê?
- É socialmente aceito o fato de que acertar 60% das vezes alguma suposição é considerado um sucesso. Mas se podemos prever como as pessoas agirão, não deveríamos sempre acertar? Ou seja, não estamos fazendo algo de forma errada?
- Ensinando as máquinas a agirem por si só, contaremos com o apoio de alguém cuja capacidade e paciência de aprender podem se sobressair a qualquer outro sujeito já visto na história. A cada dia estamos mais perto de atingir algum resultado realmente satisfatório, diminuindo a porcentagem de erros pouco a pouco, fazendo com que 60% nunca mais seja sinônimo de sucesso.
- Como a máquina aprende?
- Já previamente citado acima, o processo de aprendizagem de uma máquina se baseia na análise de massivas quantidades de dados, principalmente nos resultados anteriormente obtidos em testes. Testes esses que são gerados pelos softwares, que constroem previsões de aplicação, mesmo sem alterar seu código fonte.

- Como desenvolver uma aplicação de Machine Learning?
- Coletar dados
- Você pode coletar dados procurando manualmente por websites ou livros, pegar informações de alguma API, possuir um sistema previamente programado para procurar e enviar tais dados para você, o leque de possibilidades é imenso.
- Preparar os dados de entrada
- Não basta só obter os dados necessários, é preciso também fazer com que os mesmos passem a possuir um formato utilizável, que ajude você a construir e manusear de forma prática o algoritmo.
- Analisar os dados de entrada
- Tendo como objeto os dados da tarefa anterior, é necessário analisar os dados, em busca de qualquer padrão óbvio, se esse existir – como, por exemplo, um conjunto de dados específico que difere muito do resto.
- É cabível, também, separar o objeto a ser analisado em diferentes camadas (ou dimensões), para facilitação da análise. Entretanto, na maioria das vezes você vai se deparar com bem mais do que três características a serem divididas, tornando difícil fazer uma análise precisa de primeira.
- Para ajudar, nesses casos, podem ser usados métodos avançados que filtram múltiplas dimensões, a fim de diminuí-las para um número confortável para ser analisado.
- Treinar o algoritmo
- Nesse passo realmente a Machine Learning começa a tomar conta. Você alimenta o algoritmo com dados e extrai informação ou conhecimento. É necessário que você armazene tal conhecimento de uma forma legível para a máquina usar nos próximos passos.
- Testar o algoritmo
- Agora a informação obtida e armazenada no último passo será utilizada. Ao testar e avaliar o algoritmo, você verá o quão bem ele faz o que fora proposto pra fazer. Se for uma “supervised learning” (aprendizagem supervisionada), você pode colocar valores e casos que conhece para serem testados, e se for uma “unsupervised learning” (aprendizagem não supervisionada), você terá de usar outros métodos para obter o sucesso.
- Usar o algoritmo
- Aqui, após revisar todos os passos, você realmente possui um programa com uma determinada função.
- Coletar dados
- Por que Python?
- Para realmente construir um sistema que utilize Machine Learning, é necessária a utilização de alguma linguagem de programação popular, de fácil entendimento e com um grupo ativo de desenvolvimento. Tendo isso em vista, Python está no topo ao analisar tais exigências como um todo.
- Python possui uma sintaxe muito simples, além de ser bem acessível para qualquer tipo de pessoa, pois oferece também um enorme leque de possibilidades, podendo ser utilizada para programação procedural, orientada a objeto, funcional e etc.
- A linguagem conta também com um número imensurável de bibliotecas – de fácil localização e instalação também –, além da fácil e intuitiva manipulação de texto.
- O que difere Python das demais populares linguagens? Exemplos como Java e C são bem-vindos: ambas contam com um grande número de linhas de código para qualquer tipo de problema, desde a declaração de variáveis até a saída de dados. Python é concisa e fácil, tanto para ler quanto codificar, o que a torna bem mais acolhedora, até mesmo para quem nunca programou na vida.
- Por que Python?

- Exemplos
- Carros autônomos
- Recomendações de sites como a Amazon ou aplicações como o Spotify
- Análise de cotações da Bolsa

- Referências bibliográficas
- Conceito e exemplos
- Conceito, importância e processos de desenvolvimento
- Livro Machine Learning in Action, de Peter Harrington (Caps. 1.1; 1.5; 1.6)
- Imagens usadas
- adelaide.edu.au
- bleepingcomputer.com
- startupi.com.br
- news.allaboutjazz.com
Memória RAM
- Conceito
- Memória de Acesso Aleatório ou RAM, é o hardware físico dentro de um computador que armazena dados temporariamente, servindo como a memória "de trabalho" do computador.
- Adicionar mais RAM permite que um computador trabalhe com mais informações ao mesmo tempo, o que geralmente tem um efeito considerável no desempenho total do sistema.
- Seu computador usa RAM para carregar dados porque é muito mais rápido do que executar os mesmos dados diretamente de um disco rígido.
- Funcionamento
- Pense na RAM como uma mesa de escritório. Uma mesa é usada para acesso rápido a documentos importantes, ferramentas de escrita e outros itens de que você precisa no momento . Sem uma escrivaninha, você manteria tudo armazenado em gavetas e armários, significando que levaria muito mais tempo para realizar suas tarefas diárias, já que você teria que constantemente entrar nesses compartimentos de armazenamento para obter o que precisa, e depois gastar mais tempo colocando afastados.
- Da mesma forma, todos os dados que você está usando ativamente em seu computador (ou smartphone, tablet , etc.) são armazenados temporariamente na RAM. Esse tipo de memória, como uma mesa na analogia, fornece tempos de leitura / gravação muito mais rápidos do que o uso de um disco rígido. A maioria dos discos rígidos é consideravelmente mais lenta que a RAM devido a limitações físicas, como velocidade de rotação.
- Ao contrário de um disco rígido, que pode ser desligado e ligado novamente sem perder seus dados, o conteúdo da RAM é sempre apagado quando o computador é desligado. É por isso que nenhum dos seus programas ou arquivos ainda estão abertos quando você liga o computador novamente.
- RAM no seu computador
- Um módulo padrão ou gravador de memória de mesa é um hardware longo e fino que se parece com uma régua curta. A parte inferior do módulo de memória possui um ou mais entalhes para orientar a instalação adequada e é revestida com vários conectores, geralmente banhados a ouro.
- A memória está instalada nos slots do módulo de memória localizados na placa-mãe . Esses slots são fáceis de encontrar - basta olhar para as pequenas dobradiças que prendem a RAM no lugar, localizadas em ambos os lados do slot de tamanho similar na placa-mãe.

- Referências bibliográficas:
Memória ROM
- Conceito
- A memória somente de leitura ou ROM (acrônimo em inglês de read-only memory) é um tipo de memória que permite apenas a leitura, ou seja, as suas informações são gravadas pelo fabricante uma única vez e após isso não podem ser alteradas ou apagadas, somente acessadas. São memórias cujo conteúdo é gravado permanentemente.
- Uma memória somente de leitura propriamente dita vem com seu conteúdo gravado durante a fabricação. Atualmente, o termo Memória ROM é usado informalmente para indicar uma gama de tipos de memória que são usadas apenas para a leitura na operação principal de dispositivos eletrônicos digitais, mas possivelmente podem ser escritas por meio de mecanismos especiais.
- Funcionamento
- Memória apenas de leitura (ROM), também conhecida como firmware, é um circuito integrado (chip) programado com dados específicos, no momento de sua construção. Circuitos integrados de ROM não são usados somente em computadores, mas em muitos outros equipamentos eletrônicos.
- Tipos de Memória ROM
- Existem 5 tipos básicos de ROM:
•ROM •PROM •EPROM •EEPROM •memória Flash
Modelo Orientado a Serviço
- Conceito
- Arquitetura Orientada a Serviço é um modelo de planejamento de estratégia da área de tecnologia da informação, alinhando diretamente aos objetivos de negócios de
uma organização que permite expor as funcionalidades os aplicativos em serviços padronizados e inter-relacionados. Essa arquitetura tem como objetivo integrar as aplicações, disponibilizar maior flexibilidade para mudanças, suportar serviços independentes de plataforma e protocolos. SOA trata os requisitos de baixo acoplamento, desenvolvimento baseado em padrões, computação distribuída independentemente de protocolo, integração de aplicação e sistemas legados, seu componente mais importante é o ESB ( Barramento de Serviço Corporativos), não implementa a arquitetura, mas oferece as funcionalidades para implementá-las. Seu maior foco é a construção e disponibilização de serviços de negócio, evitar replicação de dados, reuso e facilidade de manutenção de sistemas, integração entre sistemas, visão e controle do processo de negócio, agilidade na mudanças.
- Serviço: são módulos de negócios ou funcionalidades que possuem interfaces expostas que são invocadas via mensagens, estas que disponibilizam recursos sem que a implementação do serviço seja conhecida.Trata-se de um estilo arquitetônico de construção de aplicações de software que promove baixo acoplamento entre componentes, de modo que possam ser reutilizados, é uma nova forma de construir aplicações com as seguintes características:
• Um serviço pode assumir dois papéis em uma arquitetura orientada a serviços: – Servidor/Provedor
• Prestador de um serviço.
• Possui interface publicada com a descrição dos serviços prestados.
– Cliente/Consumidor
• Solicita (consome) serviços de um provedor.
- Vantagens da Arquitetura Orientada a Serviço
Tem como vantagem o reuso de serviços, aumentando produtividade, alinhamento com negócios, melhorias para corporação e facilidade na gerencia da tecnologia da informação, focando em melhorias continuas e automatizando os processos, disponibilizando qualidade de informações trafegadas na empresa.
Abaixo são listadas algumas vantagens que ela pode trazer para o negócio.
- Reutilização: O serviço pode ser reutilizado para outras aplicações.
- Produtividade: Com o reuso, a equipe de desenvolvimento pode reutilizar serviços em outros projetos, diminuindo o tempo de desenvolvimento.
- Flexibilidade: Isolando a estrutura de um serviço as mudanças são feitas com maior facilidade.
- Manutenibilidade: Com baixo acoplamento, facilita a manutenção dos serviços.
- Alinhamento com o negócio: A área de negócio visualiza os processos alinhados com a tecnologia.
- Interoperabilidade: Disponibilizar serviços independentemente da plataforma e tecnologia.
- Integração: A integração com outros serviços, aplicativos e sistemas legados.
- Governança: Gerenciamento nos processamentos de negócio.
- Padronizado: É baseado no uso de padrões.
- Abstração: Serviço totalmente abstraído da sua implementação.
- Desvantagens
Sua desvantagem é a questão de segurança. Pois, ela depende da implantação de normas, não é utilizada em aplicações com frande transferência de dados, altos acoplamentos e aplicações que precisam manter estado.
A seguir são listadas algumas desvantagens.
- Siga os padrões de mercado: WS-I, WS-BPEL, WSDL, UDDI, SOAP.
- Use ESB (Enterprise Service Bus): É um mecanismo arquitetural para comunicação corporativa que possibilita a integração de sistemas.
- Siga os princípios de SOA: Fraco acoplamento, contrato de interfaces, serviços reutilizáveis, não manter estado entre chamadas.
- Use nomes de negócio para os serviços: Os consumidores dos serviços não sabem o que acontece dentro dos serviços, então os nomes dos serviços devem usar terminologias e vocabulário para tornar seu significado intuitivo.
- Estabeleça padrõe[[Arquivo:s de nomenclatura: Facilita na leitura e o significado dos serviços.
- Seja cético na candidatura de serviços: Nem tudo precisa ser um serviço. Explore sistemas que já existem para procurar candidatos a serviços, verificar o valor para o negócio e não para a TI.
- Otimize mensagens SOAP: O conteúdo do SOAP é XML. Trafegar grandes informações pode ser um problema, devido à quantidade de tags em torno dos dados. Procure um mecanismo mais eficiente de serialização de XML.
- Crie serviços que tenham operações atômicas: O serviço não deve se preocupar com dados de outros serviços, serviços devem funcionar sem transação e estornos de dados.
- 'Construa seus serviços iterativamente: Não tente criar tudo em um serviço ao mesmo tempo, comece com uma área ou grupo de processos que traga valor agregado no negócio.
- Contrate uma consultoria: Não tente implantar SOA sem ajuda externa, é um estilo arquitetural difícil de aplicar.
Segue abaixo alguns ESTILOS DA ARQUITETURA
Camadas : Em uma visão abstrata a arquitetura SOA é retratada como uma arquitetura particionada em várias camadas compostas por serviços que são
alinhados com os processos de negócio. Para cada uma das camadas, deve ser feito o design e as decisões arquiteturais. Por isso, na documentação de SOA deve ser criado um documento constituído por seções que correspondem a cada uma das camadas.
• Nível 1: Sistemas Operacionais;
• Nível 2:Componentes Empresariais;
• Nível 3:Serviços;
• Nível 4:Composição de processos de negócio ou Coreografias;
• Nível 5:Acessos ou Apresentação;
• Nível 6:Integração;
• Nível 7: Qualidade de Serviços.
Web Services: é uma solução utilizada na integração de sistemas e na comunicação entre aplicações diferentes, com esta tecnologia novas aplicações podem interagir com aquelas que já existem e que sistemas desenvolvidos em plataformas diferentes sejam compatíveis. Os Web Services são componentes que permitem às aplicações enviar e receber dados em formato XML, sendo assim cada aplicação pode ter a sua própria "linguagem" que é traduzida para uma linguagem universal, o formato XML.
Web Service tem que ser visto por um conjunto de tecnologias, que são citadas por MARZULLO (2009).
Protocolo HTTP: Transmissão de dados pela Internet.
XML: Formato padrão para troca de informações, os dados são separados por tags.
SOAP: Fornece uma estrutura padrão de empacotamento para transporte de documentos XML pela internet.
WSDL: Tecnologia XML que descreve de forma padronizada a interface de um Web Service.
UDDI: Descreve um registro mundial de serviços e serve com integração, propaganda e descoberta de serviços.

SOA e API são conceitos conhecidos e bastante populares na área de TI. Nos últimos anos SOA acabou tendo um destaque muito maior enquanto que mais recentemente o conceito de API voltou com força a ocupar espaço nos noticiários.
- API é um termo bem antigo. Refere-se a interfaces providas por componentes ou bibliotecas de softwares que podem ser usadas para a programação de aplicativos. Ou seja, ao construir um determinado produto ou sistema (seja um dispositivo, biblioteca de software, componente ou outros) em geral se define uma camada que permita utilizar e se comunicar com ele. Esta camada é a sua API.
Implantar SOA
A primeira etapa é identificar desafios ou prioridades comerciais importantes à integração, alguns dos princípios implantados em SOA são escolhidos de modo que atendam as necessidades comercias, ofereçam um bom tempo para concretizar o valor e dando o melhor suporte ao crescimento de longo prazo para as empresas (MICROSOFT, 2012). Os desafios de fornecer aplicações baseadas em SOA está em identificar os problemas que podem acontecer e ter um plano para resolvê-los sem ter impactos na implementação. Para que seja bem sucedida, precisa de uma arquitetura de referência bem estruturada e planejada, precisam de pessoas que lideram a abordagem orientada a serviço.
Segue abaixo alguns desafios:
- Não sabem explicar o valor de SOA para o negócio.
- Barreiras politicas.
- Gerência do ciclo de vida de serviços.
- Cultura organizacional.
- Estrutura de processos de governança.
- Imaturidade de competências.
- Falta de experiência na implementação.
Para ter uma implementação bem sucedida, depende da abordagem cuidadosa do planejamento da arquitetura de negócios. A ferramenta mais importante é o conjunto de boas práticas. Aprender com as experiências das empresas que já passaram pelos processos de implantação é um bom começo para ter sucesso na implementação de SOA. (FRONCKOWIAK, 2012).
SOA é considerado como chave para melhorar a eficiência de TI, mais para implementar o negócio, é preciso ter muito mais do que apenas conhecimento técnico, e sim fornecer serviços com mais segurança e conscientização das pessoas que estão envolvidas no processo.SOA é considerado como chave para melhorar a eficiência de TI, mas para implementar em um negócio, é preciso ter muito mais do que apenas conhecimento técnico. É essencial aprimorar as habilidades em práticas de gestão, utilizando as melhores práticas em relação a SOA. Abaixo algumas poucas práticas:
- Siga os padrões de mercado: WS-I, WS-BPEL, WSDL, UDDI, SOAP.
- Use ESB (Enterprise Service Bus): É um mecanismo arquitetural para comunicação corporativa que possibilita a integração de sistemas.
- Siga os princípios de SOA
- Use nomes de negócio para os serviços
- Estabeleça padrões de nomeclatura
- Seja cético na candidatura de serviços
- Otimize mensagens SOAP
- Crie serviços que tenham operações atômicas
- Construa seus serviços iterativamente
- Contrate uma consultoria
- Desta forma chegamos a um conclusão que à abordagem tradicional de desenvolvimento de software não é mais capaz de trazer vantagens à organização, e que SOA responde de forma efetiva e rápida aos negócios.
- Segue baixo alguns modelos de Arquitetura Orientada a Serviço:



* Referências bibliográficas:
https://www.devmedia.com.br/vantagens-e-desvantagens-de-soa/27437
https://www.treinaweb.com.br/blog/voce-sabe-o-que-e-arquitetura-orientada-a-servicos-soa/
https://www.profissionaisti.com.br/2017/05/soa-principios-de-projetos-orientados-a-servico/
https://www.youtube.com/watch?v=vo-MYUsuFms
http://www.revistaintellectus.com.br/DownloadArtigo.ashx?codigo=84
Modem
- Conceito
- O desenvolvimento de novas tecnologias tornou real a possibilidade de virtualização de uma máquina, permitindo a operação de diversos sistemas somente em âmbito digital. Contudo, para essa virtualização foi necessário o desenvolvimento de modernas técnicas de modulação digital. Neste contexto entra o Modem, dispositivo que modula um sinal digital em sinal analógico, capaz de ser transmitido pela linha telefônica por exemplo, e também demodula o sinal analógico convertendo-o novamente em sinal digital.

Exemplo de modem conectado a um roteador.
- Tipos
- Para esta tecnologia,capaz de comunicar dois pontos através da modulação e demodulação, surgem propostas de modems para oferecer aos usuários uma conexão mais rápida e com custos relativamente baixos de implementação. Como a tecnologia DSL (Linha Digital de Assinante), presente em alguns modens: atinge altas velocidades de transmissão e emprega a estrutura telefônica já existente de par de fios de cobre. A tecnologia de cable modem emprega, por sua vez, a estrutura existente de TV a cabo (CATV), composta por fibra óptica e cabos coaxiais de banda larga (HFC) .
- Há também um conjunto de variáveis de cada tipo de tecnologia utilizada em um modem: por exemplo, a tecnologia DSL não exige grandes investimentos no aprimoramento das linhas de assinante. outra variável é que Cable modem é uma tecnologia com acesso compartilhado – não é dedicado como ISDN ou DSL. Isto significa que a largura de banda disponível é compartilhada entre os usuários da mesma vizinhança, como se fosse uma rede LAN. Nas horas de pico é impossível atingir velocidades altas, devido ao congestionamento.Esse conjunto de variáveis que cercam cada tipo de tecnologia modem vão influenciar o consumidor final, que escolherá aquela tecnologia que melhor atender aos seus requisitos.
- Referências
- FERNANDES, Eduardo Almeida; DE DIPLOMAÇÃO, Projeto; ROCHOL, Jürgen. Estudo Comparativo: DSL× Cable Modem. Porto Alegre, v. 1, 1999.
- SIQUIERA, Tonny Matos. Implementacao de um modem OFDM em FPGA. 2004.
- ROCHA, MENDES Douglas. Redes de Computadores: Teoria e Prática. Novatec, São Paulo, 2007.
Normalização (BD)
- Conceito
- Normalização de um banco de dados é o processo de "correção" do mesmo, para evitar uso de dados irrelevantes e divergências de assuntos dentro de uma mesma tabela nesse.
- Contexto
- "Ao projetar um banco de dados, se temos um modelo de entidades e relacionamentos e a partir dele construirmos o modelo relacional seguindo as regras de transformação corretamente, o modelo relacional resultante estará, provavelmente, normalizado. Mas, nem sempre os modelos que nos deparamos são implementados dessa forma e, quando isso acontece, é necessário aplicar as técnicas de normalização, ou para normalizar (segundo caso citado), ou apenas para validar o esquema criado (primeiro caso citado). Aplicando as regras descritas a seguir, é possível garantir um banco de dados mais íntegro, sem redundâncias e inconsistências."
- Referências Bibliográficas
NoSQL
- Conceito
- NoSQL é uma categoria de banco de dados caracterizado por atender aos requisitos de gerenciamento de grandes volumes de dados, semi-estruturados ou não estruturados, que necessitam de alta disponibilidade e escalabilidade.
- Contexto
- O movimento denominado NoSQL ( Not only SQL) surgiu devido o fato de que a manipulação e processamento de grande quantidade de dados no contexto Big Data vem a ser um dos grandes desafios atualmente na área de Computação, haja vista que a quantidade de dados gerada diariamente em vários domínios de aplicação como, por exemplo, da Web, rede sociais, redes de sensores, dados de sensoriamento, entre diversos outros, estão na ordem de algumas dezenas, ou centenas, de Terabytes. Assim sendo, essa imensa quantidade de dados gerados traz novos grandes desafios na forma de manipulação, armazenamento e processamento de consultas em várias áreas de computação, e em especial na área de bases de dados, mineração de dados e recuperação de informação. Nesse contexto, os Sistemas Gerenciadores de Bases de Dados (SGBD) tradicionais não são os mais adequados, ou “completos”, às necessidades do domínio do problema de Big Data, como por exemplo: execução de consultas com baixa latência, tratamento de grandes volumes de dados, escalabilidade elástica horizontal, suporte a modelos flexíveis de armazenamento de dados, e suporte simples a replicação e distribuição dos dados.
- Tipos de ferramentas do NoSQL
- Baseado em Coluna (Column Stores): Hbase, Cassandra, Hypertable, Accumulo e Amazon SimpleB.
- Baseado em Documentos (Document Stores): MongoDB, CouchDB e BigCouch.
- Baseado em Grafos (Graph-Based Stores): Infinite Graph, Sones e HyperGraphDB.
- Baseado em Chave-Valor (Key-Value Stores): Dynamo, Azure Table Storage,Couchbase Serve, Riak e Redis.
- Exemplos de empresas que utilizam algumas dessas ferramentas dessa categoria de bancos de dados:
- Twitter;
- Facebook;
- Google;
- Amazon.
- Características
- Escalabilidade horizontal;
- Ausência de esquema ou esquema flexível;
- Suporte nativo a replicação;
- API simples para acesso aos dados;
- Consistência eventual;
- Consistência eventual.
- Referências bibliográficas
Open Source
***Definicão.
- Open Source nada mais é do que um software com código fonte aberto. Ele proporciona que o usuário tenha uma liberdade maior sobre ele, podendo adequá-lo de acordo com suas necessidades. Além de te dar uma liberdade maior para mexer com o software, pelo código fonte ser livre, te permite acessá-lo e observar tudo o que acontece dentro do programa, evitando que algum código malicioso seja colocado dentro do software. Além disso, qualquer empresa ou organização pode utilizar a licença do programa. Todos os ramos estão legíveis a utilização. Sendo assim, não é possível impedir que alguma pessoa ou empresa utilize desse software da maneira que bem entender.O Open Source foi desenvolvido pelos fundadores da OSI(Open Source Initiative – Iniciativa pelo Código Aberto), com a finalidade de apresentar os softwares para as empresas de uma maneira mais comercial. Por isso, sua atuação principal é conferir quais licenças se enquadram nos softwares livres e promover suas vantagens econômicas e tecnológicas. Nos últimos anos, um dos maiores sucessos no campo de softwares livres foi o sistema operacional Linux. Pela internet, é possível baixar o código fonte do sistema e modificá-lo inteiro, da maneira em que o usuário achar melhor. Grandes empresas do ramo de informática como a HP, Oracle, Mandriva e Google já colaboraram no desenvolvimento e melhorias do Linux.
***Distribuição de licença.
- Os direitos ao software estão qualificados para todas as pessoas que fizeram o uso dele. E deve ser aplicada mesmo que distribuídos para várias pessoas, sem que as licenças originais sejam alteradas.
***Exemplos
- 1. Firefox
- 2. Filezilla
- 3. OpenOffice
- 4. Thunderbird
Periféricos
- Conceito:
- Periféricos são dispositivos acessórios que conectam-se em uma entrada do computador para exercerem diversas funcionalidades.

- Funcionalidades:
- Os periféricos servem como uma forma de facilitar ou mesmo disponibilizar algumas funções, como imprimir folhas de um texto em um computador ( impressora ), movimentar o cursor de navegação ( mouse ), entre outros.
- Tipos de periféricos:
- De entrada: enviam informação para o computador processar.
- De saída: transmitem informação do computador para o utilizador.
- De processamento: processam a informação que a unidade central de processamento enviou.
- De entrada e saída: enviam e recebem informação do computador, muitos destes periféricos dependem de uma placa específica, como no caso das caixas de som, que precisam da placa de som.
- De armazenamento: armazenam informações do computador e permitem seu uso pra backups e transferência de arquivos.
- Externos: equipamentos que são adicionados a um periférico; equipamentos a parte que fornecem e/ou encaminham dados.
- Exemplos dos mais conhecidos:
- De entrada: teclado, mouse.
- De saída: monitor, impressora, caixas de som.
- De processamento : porta usb, porta de infra vermelho
- De entrada e saída: monitor, touch screen, drive de CD – DVD, modem.
- De armazenamento: pen drive, cartão de memória.

- História dos periféricos:
- Em 1952 o Comando Marítimo das Forças Canadenses, em parceria com empresas e universidades criaram o primeiro periférico do mundo(excluindo as ideias da época de mouse e teclado pois já haviam sido feitos com os computadores), uma máquina que compartilhava dados de sonares e radares em tempo real. Assim, em combate, os soldados poderiam ter uma visão unificada do campo de batalha. Este protótipo se chamava DATAR.
- Referencias bibliográficas:'
- https://pt.wikipedia.org/wiki/Perif%C3%A9rico
- https://www.portaleducacao.com.br/conteudo/artigos/informatica/o-que-sao-perifericos-de-um-microcomputador/66365
- http://www.inf.ufsc.br/~j.barreto/cca/perifer/perifericos.htm
- https://www.techtudo.com.br/noticias/noticia/2015/06/mouse-conheca-historia-deste-periferico-tao-importante-atualmente.html
Plataformas
- Conceito
- É definido como um ambiente no qual o usuário contrata para as aplicações variadas estarem alocadas. Aplicações estas como gerenciamento de aplicações, de dados e de diversos serviços por meio da internet.
- Funcionalidade
- Este dá aos desenvolvedores as ferramentas necessárias para criar e hospedar aplicativos Web. Desenvolvida com o intuito de proporcionar aos usuários o acesso aos componentes necessários para desenvolver e operar rapidamente aplicativos Web ou móveis na Internet, sem se preocupar com a configuração ou gerenciamento da infraestrutura subjacente dos servidores, armazenamento, redes e bancos de dados.
- Diferentes tipos de Nuvens/Plataforma
- Com a existência de diversos tipos de plataformas que disponibilizam estes serviços, houve a criação de nuvem de funcionamento e conceitos diferentes.
- Assim como
- Nuvem Privada: refere-se aos serviços de computação em nuvem oferecidos pela Internet ou por uma rede interna privada somente a usuários selecionados e não ao público geral, a computação em nuvem privada proporciona às empresas muitos dos benefícios de uma nuvem pública, incluindo autoatendimento, escalabilidade e elasticidade, com customização e controle adicional disponíveis de recursos dedicados em uma infraestrutura de computação hospedada localmente.
- Nuvem Publica: É uma série de serviços de computação oferecidos por terceiros à Internet pública. Eles podem ser gratuitos ou vendidos sob demanda, permitindo que os clientes paguem apenas pelo seu consumo de ciclos de CPU, armazenamento ou largura de banda.
- Nuvem Hibrida: É um ambiente de computação em que se é combinado a nuvem publica com a nuvem privada, compartilhando os dados e aplicações contidas em ambas. As organizações ganham a flexibilidade e o poder computacional da nuvem pública para tarefas de computação básicas, mantendo aplicativos e dados essenciais para os negócios no local, com segurança atrás do firewall de uma empresa.
- Assim como
- Com a existência de diversos tipos de plataformas que disponibilizam estes serviços, houve a criação de nuvem de funcionamento e conceitos diferentes.
- Plataformas mais conhecidas
- Amazon Web Services (AWS): presente em 21 países, a AWS é atualmente uma das mais famosas do ramo, por apresentar diversos serviços na área de machine learning, internet das coisas, aplicativos empresariais, robótica, serviços de multimídia, etc.

- Google Cloud Plataform (GCP): presente em 18 países, o GCP além de oferecer vários serviços semelhantes ao AWS ele aposta em seu diferencial de alta segurança, baixa latência e maior capacidade de resposta, além de preços consideravelmente menores dos que oferecido pelos concorrentes.

- Microsoft Azure: presente 54 países, a Azure oferece os mesmos diversos tipos de serviços contidos em ambas as plataformas citadas anteriormente, contudo o tipo de nuvem o qual ela oferece é a hibrida, e que possui a melhor qualidade do mercado. Sua segurança e tecnologia são tão avançados que 95% das 500 maiores empresas dos EUA a utilizam para negócios.
- Referências Bibliográficas
Portas
- Conceito:
- Portas, na computação, são um conjunto de 16 bits conhecido como port number, adicionado a um endereço de IP, e são um meio de comunicação na rede.
- Enquanto a utilidade de um endereço de IP é a de identificar um computador em uma rede, a porta identifica uma aplicação em um computador.
- São divididas em dois principais protocolos de transporte: Transmission Control Protocol (TCP) e User Datagram Protocol (UDP).
- Protocolos TCP e UDP:
- TCP:
- Considerado o protocolo de rede mais importante devido ao fato de formar o modelo TCP/IP que compõe toda a internet. É o mais utilizado atualmente, pois suas características permitem uma maior flexibilidade de usabilidade, sendo as principais características:
- Retornar uma resposta de sucesso quando todos os segmentos foram transferidos corretamente;
- Agrupar segmentos fora de ordem;
- Controlar fluxo;
- Manter conexões lógicas;
- Realizar transferências simultâneas em ambas as direções.
- Considerado o protocolo de rede mais importante devido ao fato de formar o modelo TCP/IP que compõe toda a internet. É o mais utilizado atualmente, pois suas características permitem uma maior flexibilidade de usabilidade, sendo as principais características:
- UDP:
- O UDP é considerado um protocolo menos confiável e mais simples, devido ao fato de não manter conexões. O funcionamento do User Datagram Protocol é de apenas enviar dados, sem receber nenhuma confirmação da recepção ou possibilitar transferências simultâneas.
- Seu uso pode parecer inútil inicialmente, porém há casos onde o fato da possibilidade de perda de dados será utilizado positivamente, como em streaming de vídeos, onde uma instabilidade se usado o pacote TCP causaria congelamento de imagens, já com UDP manteria rodando, apenas com a merda de alguma qualidade.
- O UDP é considerado um protocolo menos confiável e mais simples, devido ao fato de não manter conexões. O funcionamento do User Datagram Protocol é de apenas enviar dados, sem receber nenhuma confirmação da recepção ou possibilitar transferências simultâneas.
- Ambos os pacotes podem ser analisados e recusados por um firewall, que tem como principal funcionalidade analisar os pacotes recebidos e controlar o fluxo desses dados através de regras.
- TCP:
- TCP/IP:
- Também chamado de pilha de protocolos TCP pois é um conjunto de protocolos divididos em quatro camadas, que garantem a integridade do pacote na rede, sendo elas:
- Camada de Aplicação:
- Utilizada para iniciar o envio e receber informações na rede.
- Camada de Transporte:
- Recebe os dados da camada acima, verifica a integridade e divide em pacotes.
- Camada de Rede:
- Anexa os pacotes a um endereço de IP do remetente e do destinatário.
- Camada de Interface:
- Finalizar o envio de pacotes pela rede.
- Camada de Aplicação:
- Também chamado de pilha de protocolos TCP pois é um conjunto de protocolos divididos em quatro camadas, que garantem a integridade do pacote na rede, sendo elas:
- Veja a seguir como funciona o envio de um pacote em uma transmissão TCP/IP:
- Estação: SYN (solicita a abertura da conexão)
- Servidor: SYN (confirma o recebimento e avisa que a porta está disponível)
- Servidor: ACK (inicia a conexão)
- Estação: ACK (confirma)
- Estação: DATA (é enviado o pacote com a mensagem de texto)
- Servidor: OK (a confirmação, depois de verificar a integridade do pacote)
- Estação: FYN (solicita o fechamento da conexão)
- Servidor: FYN (confirma)
- Estação: FYN (confirma que recebeu a confirmação)
- Principais portas padrões:
- APLICAÇÃO: PORTA
- HTTP: 80 (WEB)
- HTTPS: 443 (SSH WEB)
- FTP: 21 (File Transfer Protocol)
- DNS: 53 (Domain Name Server)
- MySQL: 3306 (Banco de dados)
- Exemplos de aplicações rodando em portas:

Primeiramente, é necessário liberar as portas nas configurações de seu roteador e firewall
Netcat rodando na porta 9999 pelo bash do linux.

Servidor aberto com nodejs.
- Referências bibliográficas:
- Protocolo e serviços de rede - Prof. Renan Osório Rios
- Firewall Patterns - Markus Schumacher
- Hardware - www.hardware.com.br
Processadores
- Como surgiu?
Em 1945, a ideia de uma unidade central de processamento capaz de executar diversas tarefas foi publicada por John Von Neumann. Chamado de EDVAC, o projeto desse computador foi finalizado em 1949. Essa é a origem dos primeiros modelos “primitivos” de processadores da forma como os conhecemos. Porém foi só no início da década de 70 que surgiram as CPUs desenvolvidas totalmente em circuitos integrados e em um único chip de silício. O Intel 4004 foi o primeiro microprocessador a ser lançado, em 1971. Sendo desenvolvido para o uso em calculadoras, essa CPU operava com o clock máximo de 740 KHz e podia calcular até 92 mil instruções por segundo, ou seja, cada instrução gastava cerca de 11 microssegundos. A evolução dos anos 70 para os dias atuais foi tão grande que passamos de microprocessadores que trabalhavam com clock de dezenas de KHz e que podiam processar alguns milhares de instruções por segundo, para microprocessadores com clocks na casa dos 7 GHz e poder de processamento de dezenas de bilhões de instruções por segundo. A complexidade também cresceu: de alguns milhares de transístores para centenas de milhões de transístores numa mesma pastilha.
- Conceito
O processador (CPU) é um chip normalmente feito de silício que responde pela execução das tarefas cabíveis a um computador. A sua função é acelerar, endereçar, resolver ou preparar dados, dependendo da aplicação. Basicamente, um processador é uma poderosa máquina de calcular: Ela recebe um determinado volume de dados, orientados em padrão binário 0 e 1 e tem a função de responder a esse volume, processando a informação com base em instruções armazenadas em sua memória interna. O CPU tem como função principal unificar todo o sistema, controlar as funções realizadas por cada unidade funcional, e é também responsável pela execução de todos os programas do sistema, que deverão estar armazenados na memória principal.

- Velocidade
A velocidade de um processador de computador costuma ser medida pela sua frequência de processamento, que é velocidade medida em hertz, indicando a quantidade de processamentos por segundo que o processador é capaz de realizar. Por exemplo, um processador de 2,4 GHz (gigahertz), possui cerca de 2.400 MHz (megahertz), ou seja, ele é capaz de processar cerca de 2.400.000 operações por segundo.
- Clock Interno
O clock interno (ou apenas clock) atua basicamente, como um sinal para sincronismo. Quando os dispositivos do computador recebem o sinal de executar suas atividades, dá-se a esse acontecimento o nome de "pulso de clock". Em cada pulso, os dispositivos executam suas tarefas, param e vão para o próximo ciclo de clock. A medição do clock é feita em hertz (Hz), a unidade padrão de medidas de frequência, que indica o número de oscilações ou ciclos que ocorre dentro de uma determinada medida de tempo, no caso, segundos. Assim, se um processador trabalha à 800 Hz, por exemplo, significa que ele é capaz de lidar com 800 operações de ciclos de clock por segundo.
- Componentes
- ULA: é a sigla para Unidade Lógica Aritmética. Trata-se do circuito que se encarrega de realizar as operações matemáticas requisitadas por um determinado programa, ou seja, executa efetivamente as instruções dos programas, como instruções lógicas, matemáticas, desvio, etc.
- Unidade de controle: O termo “cérebro eletrônico” está longe de classificar e resumir o funcionamento de um processador. No entanto, a Unidade de Controle é o que há de mais próximo a um cérebro dentro do processador. Esse controlador é responsável pela tarefa de controle das ações a serem realizadas pelo computador, comandando todos os outros componentes.
- Memória cache: A ideia de se criar a memória cache, partiu de que a tecnologia de memória RAM não alcançou os processadores em desempenho, assim o desempenho do processador poderia ser afetado pela “lentidão” da memória. A memória cache consiste em uma pequena quantidade de memória SRAM embutida no processador. Quando este precisa ler dados na memória RAM, um circuito especial chamado "controlador de cache" transfere blocos de dados muito utilizados da RAM para a memória cache. Assim, no próximo acesso do processador, este consultará a memória cache, que é bem mais rápida, permitindo o processamento de dados de maneira mais eficiente.
- O Memory Management Unit (MMU) ou Unidade de Gerenciamento de Memória: responsável pela coordenação do funcionamento da memória. O processador só pode ser rápido se a memória RAM acompanhar. O MMU é o recurso que transforma as instruções lógicas (virtuais) em endereços físicos nos bancos de memória. O processador varre a memória atrás de dados e instruções e o MMU é o recurso que anota onde cada informação do sistema está hospedada na memória.
- Unidade de ponto flutuante: nos processadores atuais são implementadas unidades de cálculo de números reais. Tais unidades são mais complexas que ULAs e trabalham com operandos reais, também chamados de ponto flutuante, com tamanhos típicos variando entre 32, 64 e 128 bits.
- Registradores: Os registradores são pequenas memórias velozes que armazenam comandos ou valores que são utilizados no controle e processamento de cada instrução. Para "saber" o que fazer com os dados, contudo, o processador precisa de instruções. É isso que está armazenado neste tipo de memória chamada de Registrador: diversas regras que orientam a ULA a calcular e dar sentido aos dados que recebe.
Os registradores mais importantes são:
- Apontador de Instruções (PC) – Guarda o endereço da próxima instrução a ser executada; - Registrador de Instrução (RI) – Armazena a instrução que está sendo executada; - Apontador de Pilha (SP) – Guarda o endereço da pilha de execução do programa.
- Bits dos processadores
O número de bits é outra importante característica dos processadores e tem grande influência no desempenho deste dispositivo. Processadores mais antigos, como o 286, trabalhavam com 16 bits. Durante muito tempo, no entanto, processadores que trabalham com 32 bits foram muitos comuns. Alguns modelos de 32 bits ainda são encontrados no mercado, entretanto, o padrão atual são os processadores de 64 bits, como os da linha Core i7, da Intel, ou Phenom, da AMD. De forma resumida, quanto mais bits internos o processador possuir, mais rapidamente ele poderá fazer cálculos e processar dados em geral, dependendo da execução a ser feita. Isso acontece porque os bits dos processadores representam a quantidade de dados que os circuitos desses dispositivos conseguem trabalhar por vez. Um processador com 16 bits, por exemplo, pode manipular um número de valor até 65.535. Se este processador tiver que realizar uma operação com um número de valor 100.000, terá que fazer a operação em duas partes. No entanto, se um chip trabalha a 32 bits, ele pode manipular números de valor até 4.294.967.295 em uma única operação. Como este valor é superior a 100.000, a operação pode ser realizada em uma única vez.
- Processadores com dois ou mais núcleos
É possível encontrar no mercado, atualmente, placas-mãe que contam com dois ou mais slots para processadores. A maioria esmagadora destas placas são usadas em computadores especiais, como servidores e workstations, equipamentos direcionados a aplicações que exigem muito processamento. Para atividades domésticas e de escritório, no entanto, computadores com dois ou mais processadores são inviáveis devido aos elevados custos que arquiteturas do tipo possuem. Um dos principais problemas enfrentados pelos fabricantes no quesito de se criar um processador veloz é a questão da temperatura: teoricamente, quanto mais megahertz um processador tiver, mais calor o dispositivo gerará. Uma das formas encontradas pelos fabricantes para lidar com esta limitação consiste em fabricar e disponibilizar processadores com dois núcleos (dual core), quatro núcleos (quad core) ou mais (multi core). CPUs deste tipo contam com dois ou mais núcleos distintos no mesmo circuito integrado, como se houvesse dois (ou mais) processadores dentro de um chip. Assim, o dispositivo pode lidar com dois processos por vez (ou mais), um para cada núcleo, melhorando o desempenho do computador como um todo. Processadores multi core oferecem várias vantagens: podem realizar duas ou mais tarefas ao mesmo; um núcleo pode trabalhar com uma velocidade menor que o outro, reduzindo a emissão de calor; ambos podem compartilhar memória cache; entre outros. Os resultados desses processadores foram tão positivos que, hoje, é possível encontrar processadores com dois ou mais núcleos inclusive em dispositivos móveis, como tablets e smartphones. É interessante reparar que os núcleos de um processador não precisam ser utilizados todos ao mesmo tempo. Além disso, apesar de serem tecnicamente iguais, é possível fazer com que determinados núcleos funcionem de maneira alterada em relação aos outros. Um exemplo disso é a tecnologia Turbo Boost, da Intel: se um processador quad core, por exemplo, tiver dois núcleos ociosos, os demais podem entrar automaticamente em um modo "turbo" para que suas frequências sejam aumentadas, acelerando a execução do processo em que trabalham.

- Aplicação
Existem vários tipos de processadores e cada tipo de aplicação requer um determinado tipo de processador. É o caso dos nossos computadores, que usam os x86. Dispositivos compactos e com menos tipos de aplicações usam diferentes tipos de processadores. O celular, independentemente do nível de sofisticação, usa um processador SoC (sigla para System on a Chip: sistema em um chip). Isso significa que o processador em questão agrega diversos outros recursos, como chip de rádio, conectividade, processador gráfico e outros. Tem-se também os Processadores Digitais de Sinal que são microprocessadores especializados em processamento digital de sinal usados para processar sinais de áudio, vídeo, etc, quer em tempo real quer em off-line, que em geral, realizam sempre uma mesma tarefa simples. Basicamente, qualquer chip que controle algum hardware é um processador. Ele recebe dados, endereça-os e os devolve processados.
- Fontes:
https://www.tecmundo.com.br/historia/2157-a-historia-dos-processadores.htm https://www.infowester.com/processadores.php https://www.techtudo.com.br/artigos/noticia/2012/02/o-que-e-processador.html https://www.infoescola.com/informatica/processador/ https://pt.wikipedia.org/wiki/Microprocessador
Protocolos
O que são ? Protocolos de rede são um conjunto de normas que permitem que qualquer máquina conectada à internet possa se comunicar com outra também já conectada na rede. É assim que qualquer usuário consegue enviar e receber mensagens instantâneas (WhatsApp por exemplo), baixar e subir arquivos no seu site e acessar qualquer tipo de domínio na web. Os protocolos de internet funcionam como uma espécie de “língua universal” entre computadores. Independente do fabricante e do sistema operacional usado, essa linguagem é interpretada por todas as máquinas igualmente.Isso faz com que não seja necessário qualquer uso de software extra para que um computador possa entender os protocolos de rede. Assim, ele consegue se comunicar com outro computador ligado à rede mundial de computadores sem qualquer problema.
Quais são seus principais tipos ?
Para que a comunicação entre computadores seja realizada corretamente, é necessário que ambos os computadores estejam configurados segundo os mesmos parâmetros e obedeçam aos mesmos padrões de comunicação. A rede é dividida em camadas, cada uma com uma função específica. Os diversos tipos de protocolos de rede variam de acordo com o tipo de serviço utilizado e a camada correspondente. Conheça a seguir as principais camadas e seus tipos de protocolos principais:
-camada de aplicação: WWW, HTTP, SMTP, Telnet, FTP, SSH, NNTP, RDP, IRC, SNMP, POP3, IMAP, SIP, DNS, PING;
-camada de transporte: TCP, UDP, RTP, DCCP, SCTP;
-camada de rede: IPv4, IPv6, IPsec, ICMP;
-camada de ligação física: Ethernet, Modem, PPP, FDDi.
Principais protocolos existentes :
1. Protocolo TCP/IP TCP/IP é o acrônimo de dois protocolos combinados: o TCP (Transmission Control Protocol, que significa Protocolo de Controle de Transmissão) e IP (Internet Protocol, que significa Protocolo de Internet). O protocolo TCP/IP surgiu em 1969 nos Estados Unidos durante uma série de pesquisas militares da ARPANET. Ele foi criado para permitir a comunicação entre sistemas de computadores de centros de estudos e organizações militares espalhadas em vários pontos do planeta. A ideia era oferecer uma troca rápida de mensagens entre computadores conectados a uma rede inédita. E, nesse meio termo, identificar as melhores rotas entre dois locais, mas também encontrar rotas alternativas, quando necessárias, ou seja, um protocolo que garantisse a conexão mesmo em caso de um catástrofe nuclear.
2. Protocolo HTTP/HTTPS O protocolo HTTP (Hypertext Transfer Protocol — Protocolo de Transferência de Hipertexto) é usado para navegação em sites da internet. Funciona como uma conexão entre o cliente (browser) e o servidor (site ou domínio). O navegador envia um pedido de acesso a uma página, e o servidor retorna uma resposta de permissão de acesso. Junto com ela são enviados também os arquivos da página que o usuário deseja acessar.Já o HTTPS (Hyper Text Transfer Secure — Protocolo de Transferência de Hipertexto Seguro) funciona exatamente como o HTTP, porém, existe uma camada de proteção a mais. Isso significa que os sites que utilizam esse protocolo são de acesso seguro. O protocolo HTTPS é comumente usado por sites com sistemas de pagamentos. Esse tipo de site depende de proteção que garanta a integridade dos dados, informações de conta e cartão de créditos dos usuários. A segurança é feita por meio de uma certificação digital, que cria uma criptografia para impedir ameaças e ataques virtuais.
3. FTP Significa Protocolo de Transferência de Arquivos (do inglês File Transfer Protocol). É a forma mais simples para transferir dados entre dois computadores utilizando a rede. O protocolo FTP funciona com dois tipos de conexão: a do cliente (computador que faz o pedido de conexão) e do servidor (computador que recebe o pedido de conexão e fornece o arquivo ou documento solicitado pelo cliente). O FTP é útil caso o usuário perca o acesso ao painel de controle do seu site. Assim sendo,essa ferramenta pode ser usada para realizar ajustes página, adicionar ou excluir arquivos, ou aimda solucionar qualquer outra questão no site.
4. SFTP Simple Transfer Protocol (Protocolo de Transferência Simples de Arquivos) consiste no protocolo FTP acrescido de uma camada de proteção para arquivos transferidos. Nele, a troca de informações é feita por meio de pacotes com a tecnologia SSH (Secure Shell – Bloqueio de Segurança), que autenticam e protegem a conexão entre cliente e servidor. O usuário define quantos arquivos serão transmitidos simultaneamente e define um sistema de senhas para reforçar a segurança.
5. SSH SSH (Secure Shell, já citado acima) é um dos protocolos específicos de segurança de troca de arquivos entre cliente e servidor. Funciona a partir de uma chave pública. Ela verifica e autentica se o servidor que o cliente deseja acessar é realmente legítimo. O usuário define um sistema de proteção para o site sem comprometer o seu desempenho. Ele fortifica a segurança do projeto e garante maior confiança e estabilidade na transferência de arquivos.
6. SSL O protocolo SSL (Secure Sockets Layer — Camada de Portas de Segurança) permite a comunicação segura entre os lados cliente e servidor de uma aplicação web, por meio de uma confirmação da identidade de um servidor e a verificação do seu nível de confiança. Funciona com a autenticação das partes envolvidas na troca de informações. A conexão SSL é sempre iniciada pelo cliente, que solicita conexão com um site seguro. O browser, então, solicita o envio do Certificado Digital e verifica se ele é confiável, válido, e se está relacionado ao site que fez o envio. Após a confirmação das informações, a chave pública é enviada e as mensagens podem ser trocadas.
7. ICMP Sigla para Internet Control Message Protocol (Protocolo de Mensagens de Controle da Internet). Esse protocolo autoriza a criação de mensagens relativas ao IP, mensagens de erro e pacotes de teste. Ele permite gerenciar as informações relativas a erros nas máquinas conectadas. O protocolo IP não corrige esses erros, mas os mostra para os protocolos das camadas vizinhas. Por isso, o protocolo ICMP é usado pelos roteadores para assinalar um erro, chamado de Delivery Problem (Problema de Entrega).
8. SMTP Protocolo para transferência de e-mail simples (Simple Mail Transfer Protocol) é comumente utilizado para transferir e-mails de um servidor para outro, em conexão ponto a ponto. As mensagens são capturadas e enviadas ao protocolo SMTP, que as encaminha aos destinatários finais em um processo automatizado e quase instantâneo. O usuário não tem autorização para realizar o download das mensagens no servidor.
9. TELNET Protocolo de acesso remoto. É um protocolo padrão da Internet que permite obter uma interface de terminais e aplicações pela web. Fornece regras básicas para ligar um cliente a um intérprete de comando. Ele tem como base uma conexão TCP para enviar dados em formato ASCII codificados em 8 bits, entre os quais se intercalam sequências de controle Telnet. Assim, fornece um sistema orientado para a comunicação bidirecional e fácil de aplicar.
10. POP3 Acrônimo para Post Office Protocol 3 (Protocolo de Correios 3). É um protocolo utilizado para troca de mensagens eletrônicas. Funciona da seguinte forma: um servidor de email recebe e armazena mensagens. O cliente se autentica ao servidor da caixa postal para poder acessar e ler as mensagens. Assim, as mensagens armazenadas no servidor são transferidas em sequência para o computador do cliente. Quando, a conexão é encerrada as mensagens ainda são acessadas no modo offline.
RA

- O que é?
Realidade Aumentada (RA) se baseia na integração de elementos virtuais à percepção da realidade, se trata de uma composição dos sentidos. Ela é responsável por complementar o mundo real, em oposição à Realidade Virtual (RV) que o substitui, buscando trazer objetos digitais ao mundo real a fim de trazer ao usuário maior imersão e interatividade. Conceitualmente, RA pode complementar todos os sentidos humanos, porém a tecnologia mais comumente utilizada provê componentes primariamente visuais e sonoros.
- Funcionamento
Segundo um dos precursores da ideia de RA, Ronald Azuma, é um sistema com três princípios:
- Combinar elementos virtuais ao mundo real.
- Processar essas informações em tempo real.
- Conceber qualquer ambiente em três dimensões.
- Aplicações
Provavelmente a aplicação mais conhecida em todo o mundo é o jogo mobile Pokémon Go, seguido dos famosos filtros de fotos nas redes sociais, porém as utilidades dessa tecnologia são extremamente amplos já que, nos dias atuais, praticamente todos possuem smartphones que são capazes de operar essa tecnologia. Exemplos de uso:
- Leitura de QR Codes.
- Oficinas/Indústrias: na integração de sensores do maquinário diretamente com o próprio maquinário, gerando um objeto em destaque.
- Militar: HUD para pilotos de caça, que mostram as informações dos sensores do avião (inclinação, velocidade, uso dos motores, radar, etc.)
- Reuniões: Interatividade com informações discutidas através de objetos e gráficos virtuais.
- Prototipagem de produtos: visualizar o movimento de peças móveis, simular peças adicionais, etc.
- Organização de espaço: projetar previamente objetos, como móveis em um cômodo, antes de colocá-los de fato.
- Compra de produtos: Projeta algum produto de algum catálogo



- Dispositivos
- Smartphones (utiliza primariamente a câmera)
- Eyetap
- Google Glass (projeto/produto descontinuado)
- Basicamente, um conjunto sensores (câmera, acelerômetro, entre outros) e uma forma de mostrar essas informações (tela).


- Referências Bibliográficas
- https://exame.abril.com.br/marketing/16-usos-inteligentes-de-realidade-aumentada-em-campanhas/
- https://www.apple.com/br/ios/augmented-reality/
- https://www.cs.unc.edu/~azuma/ARpresence.pdf
- https://www.linkedin.com/in/ronaldazuma
- https://www.ecommercebrasil.com.br/artigos/realidade-aumentada-tendencia-para-2019/
- https://pt.wikipedia.org/wiki/Realidade_aumentada
- http://eyetap.org/
- https://exame.abril.com.br/tecnologia/o-que-podemos-aprender-com-o-fracasso-do-google-glass/
- http://www.realidadeaumentadabrasil.com.br/
Raspberry
- Definição?
Raspberry Pi é um computador do tamanho de um cartão de crédito, que se conecta a um monitor de computador ou TV, e usa um teclado e um mouse padrão, desenvolvido no Reino Unido pela Fundação Raspberry Pi. Todo o hardware é integrado numa única placa

O Raspberry é capaz de fazer tudo o que voce esperaria de um computador desktop, como navegar na internet, reproduzir vídeo de alta definição, fazer planilhas, processamento de texto e jogar jogos.
Além do mais o Raspberry é capaz de interagir com o mundo exterior, e tem sido usado em uma ampla gama de projetos, de máquinas de música, impressões 3D, configurações de interface com objetos e etc.
- O que fazer com um Raspberry Pi?
É possível instalar o sistema operacional Linux e poder usar para funções básicas de escritório como documentos de textos e planilhas, além de poder usar para navegar a internet e realizar pesquisas. Tudo que você tem que fazer é ligar na HDMI de seu monitor ou TV e plugar um teclado e mouse USB. Ou até mesmo fazer projetos que podem facilitar e até mesmo avançar estudo que algumas ferramentas não possibilitam tal facilidade.
A seguir veja alguns projetos feitos com Raspberry Pi.
- Projetos
- Magic Mirror - Espelho Mágico
O espelho mágico foi criando com o intuito de simular uma interface comunicativa com simples informações como, data, hora, clima e etc.
Para que este espelho funcionasse, ele nao poderia ser como um espelho convencional, precisaria ser semitransparente.
A definição do monitor é feita pelo modo que a tela será usada, se será em paisagem ou retrato, neste caso como se tratava de um espelho vertical, foi usado um monitor com orientações de retrato.
As outras necessidades para este projeto foram:
-Um cabo HDMI (para conectar o Raspberry ao monitor)
-Um cabo USB para micro USB (para alimentar o Raspberry Pi)
-Um cabo de alimentação para alimentar o monitor

Após a Instalação do Hardwarde o Raspberry precisa ser configurado para a interface gráfica relacionada ao monitor.

Feito a instalação e configuração do Raspberry Pi, o espelho usa tecnologias de bilbiotecas abertas para configuração dos layouts e parâmetros, concluindo o processo do Espelho Mágico.
Resultado Final

O Raspberry além de funções simples, oferece uma gama de possbilidades de ultilização como a de um Servidor de Arquivos.
- Servidor de Arquivos
Simples e de baixo consumo, o Raspberry Pi pode ser um servidor ideal para quem deseja compartilhar seus arquivos dentro de uma rede doméstica. Usando a plaquinha, associada a um ou mais HDs, você pode construir um servidor doméstico, permitindo que você acesse seus arquivos a partir de qualquer dispositivo conectado à sua rede: documentos, fotos e vídeos podem, assim, ser distribuídos entre vários usuários.
Pode-se , até mesmo, usar unidades externas bem maiores, que precisam de suprimento extra de energia. Mas, nesse caso, estaríamos derrotando o propósito da criação de um servidor NAS doméstico simples, de baixo custo e consumo.

Após a configuração do usuário e senha o servidor de mídia esta disponível para recebimento de arquivos com sucesso.

- Fontes
https://tudosobreraspberry.info/2017/03/saiba-o-que-e-um-raspberry-pi-e-para-que-ele-serve
https://michaelteeuw.nl/post/84026273526/and-there-it-is-the-end-result-of-the-magic
Redes de Computadores
Conceito Rede de computadores é uma estrutura de computadores e dispositivos conectados através de um sistema de comunicação com o objetivo de compartilharem informações e recursos entre si. Tal sistema envolve meios de transmissão e protocolos. As conexões podem ser estabelecidas usando mídia de cabo ou mídia sem fio. Os dispositivos que originam uma rede de computadores que roteiam e terminam os dados, são denominados de “nós” de rede (ponto de conexão). Os “nós” podem incluir hosts, como computadores pessoais, telefones, servidores, e também hardware de rede. Dois desses dispositivos podem ser ditos em “rede” quando um dispositivo é capaz de trocar informações com o outro dispositivo, quer eles tenham ou não uma conexão direta uns com os outros.
Alguns benefícios que podem ser obtidas com a rede de computadores:
- Compartilhamento impressoras.
- Compartilhamento de documentos, aplicativos e outros produtos digitais.
- Facilita a replicação de dados para backup.
- Comunicação.
- Vídeo conferência.
Tipos de Rede de Computadores
LAN: Esse é o formato com o qual estamos mais habituados. A LAN (Local Area Networks) é uma rede local, ou seja, de curta distância. Ela conecta dispositivos próximos, reunidos em um mesmo ambiente, por exemplo, o escritório de uma PME ou uma residência.
CAN: A CAN (Campus Area Network) – ou seja, uma rede de campus – possui um propósito bastante parecido com a LAN. Contudo, ela já possui um alcance maior. Sua utilidade é permitir a conexão entre redes de um mesmo complexo ou condomínio, como universidades, hospitais e centros comerciais.
MAN: Para conectar as redes locais dentro de distâncias maiores, você pode utilizar a MAN (Metropolitan Area Network), que significa rede metropolitana. Ela pode ser utilizada para estabelecer uma conexão entre escritório que estão em um mesmo município ou cidades vizinhas, cobrindo algumas dezenas de quilômetros.
WAN: A WAN (Wide Area Network) é uma rede de longa distância. Sua cobertura é bastante superior à das redes LAN e MAN. Com ela é possível conectar equipamentos em diferentes localidades, de países até continentes.
RAN: RAN é a sigla para Regional Area Network, em português, rede de área regional. Conta com alcance maior que as redes do tipo LAN e MAN, porém menor que as WAN. A conexão de alta velocidade, através de fibra ótica, é uma de suas principais características.
PAN: A rede PAN (Personal Area Network), que significa rede de área pessoal, é a com maior limitação de alcance. Ela conecta apenas aparelhos que estão a uma distância curtíssima, um exemplo desse tipo de rede é o Bluetooth.
SAN: Já a rede SAN (Storage Area Network), em tradução livre, rede de área para armazenamento, tem apenas uma função. Portanto, ela é a responsável por armazenar dados da rede e fazer a comunicação entre um servidor e os demais dispositivos.
VLAN: A versão virtual da rede LAN, a VLAN (Virtual LAN), reúne diversas máquinas de forma lógica e não física. Sendo assim, ela é capaz de dividir uma LAN física, em diversas redes virtuais.
Redes sem fio:
WLAN: Uma versão da LAN mas na sua forma Wireless ( Sem fio ).
WMAN: Uma versão da MAN mas na sua forma Wireless ( Sem fio ).
WWAN: Uma versão da WAN mas na sua forma Wireless ( Sem fio ).
Tipos de Arquitetura de Rede
- ARCnet é uma rede local (LAN) Protocolo, para efeitos semelhantes em Ethernet ou Token Ring.
- Ethernet é uma arquitetura de interconexão para redes locais - Rede de Área Local (LAN) - baseada no envio de pacotes.
- Token ring é um protocolo de redes que opera na camada física (ligação de dados) e de enlace do modelo OSI dependendo da sua aplicação.
- FDDI adotam uma tecnologia de transmissão idêntica às das redes Token Ring, mas utilizando, vulgarmente, cabos de fibra óptica, o que lhes concede capacidades de transmissão muito elevadas.
- ISDN é um conjunto de padrões de comunicação para transmissão digital simultânea de voz, vídeo, dados e outros serviços de rede sobre os circuitos tradicionais da rede pública de telefonia comutada.
- Frame Relay é uma eficiente tecnologia de comunicação de dados usada para transmitir de maneira rápida e barata (qb) a informação digital através de uma rede de dados, dividindo essas informações em frames (quadros) a um ou muitos destinos de um ou muitos end-points.
- ATM é, de acordo com o ATM Forum, "um conceito de telecomunicações definido pelos padrões ANSI e ITU (formalmente CCITT) para transporte de uma variedade completa de tráfego de usuários, incluindo sinais de voz, dados e vídeo.
- X.25 baseado em uma estrutura de rede analógica, predominante na época de sua criação. É considerado o precursor do protocolo Frame Relay.
- DSL é uma família de tecnologias que são usadas para transmitir dados digitais sobre linhas telefônicas.
Bibliografia:
https://netsupport.com.br/blog/redes-de-computadores/
https://www.portalgsti.com.br/redes-de-computadores/sobre/
https://netsupport.com.br/blog/redes-de-computadores/
Redes Neurais
Conceito Redes Neurais Artificiais são técnicas computacionais que apresentam um modelo matemático inspirado na estrutura neural de organismos inteligentes e que adquirem conhecimento através da experiência. Uma grande rede neural artificial pode ter centenas ou milhares de unidades de processamento. Na sua forma mais geral, uma rede neural é uma máquina que é projetada para modelar a maneira como o cérebro realiza uma tarefa particular ou função de interesse, a rede é normalmente implementada utilizando-se componentes eletrônicos ou simulada por programação em um computador digital.
Funcionamento Uma rede neural artificial é composta por várias unidades de processamento. Essas unidades, geralmente são conectadas por canais de comunicação que estão associados a determinado peso. As unidades fazem operações apenas sobre seus dados locais, que são entradas recebidas pelas suas conexões. O comportamento inteligente de uma Rede Neural Artificial vem das interações entre as unidades de processamento da rede. A operação de uma unidade de processamento pode ser resumida da seguinte maneira:
- Sinais são apresentados à entrada;
- Cada sinal é multiplicado por um número, ou peso, que indica a sua influência na saída da unidade;
- É feita a soma ponderada dos sinais que produz um nível de atividade;
- Se este nível de atividade exceder um certo limite a unidade produz uma determinada resposta de saída.

Benefícios
Com a capacidade de processamento de informações tornam possível para as redes neurais resolver problemas complexos (de grande escala) que são muitas vezes intratáveis. Entretanto, devido a alta capacidade dessas redes, elas podem também ser usadas para vários outros tipos de problemas ou atividades.
Exemplos de uso
- Detecção de fraude em cartões de crédito.
- Reconhecimento de caracteres e de voz, também conhecido como processamento de linguagem natural.
- Diagnósticos médicos.
- Marketing direcionado.
- Predições financeiras de ações de mercado.
- Visão computacional para interpretar fotos e vídeos não-tratados (por exemplo, na obtenção de imagens médicas, robótica e reconhecimento facial).
- Criação de arte como, músicas, pinturas, escrita.

Bibliografia
http://conteudo.icmc.usp.br/pessoas/andre/research/neural/
Livro: Redes neurais princípios e pratica. 2ªEdição. Simon Haykin.
RFId
- O que é?
- Identificação por radiofrequência ou RFID (do inglês “Radio-Frequency IDentification”) é um método de identificação automática através de sinais de rádio, recuperando e armazenando dados remotamente através de dispositivos denominados etiquetas RFID. Utiliza transponders (os quais podem ser apenas lidos ou lidos e escritos) nos produtos, como uma alternativa aos códigos de barras, de modo a permitir a identificação do produto de alguma distância do scanner ou independente, fora de posicionamento. Viabiliza a comunicação de dados através de etiquetas com chips ou transponders que transmitem a informação a partir da passagem por um campo de indução. (ex: muito usado em pedágio “sem parar”).
- A Identificação por Radiofrequência (RFID) foi desenvolvida para substituir a leitura por código de barras convencional.A leitura através de código de barras necessita da aproximação do leitor sobre o código, com ângulo exato e tempo de interpretação do mesmo. Basicamente é o mesmo utilizado nos supermercados e lojas diversas.A tecnologia de leitura por RFID utiliza de uma comunicação de curto alcance que pode ser lido automaticamente por sensores na passagem do objeto portador da etiqueta RF. A mesma tarefa com mais eficiência, menos tempo e maior precisão.
- Como funciona?
- Um sistema de RFID é composto, basicamente, de uma antena, um transceptor, que faz a leitura do sinal e transfere a informação para um dispositivo leitor, e também um transponder ou etiqueta de RF (rádio frequência), que deverá conter o circuito e a informação a ser transmitida. Estas etiquetas podem estar presentes em pessoas, animais, produtos, embalagens, enfim, em equipamentos diversos.Assim, a antena transmite a informação, emitindo o sinal do circuito integrado para transmitir suas informações para o leitor, que por sua vez converte as ondas de rádio do RFID para informações digitais. Agora, depois de convertidas, elas poderão ser lidas e compreendidas por um computador para então ter seus dados analisados.
- Etiquetas RFID
- Passiva – Estas etiquetas utilizam a rádio frequência do leitor para transmitir o seu sinal e normalmente têm com suas informações gravadas permanentemente quando são fabricadas. Contudo, algumas destas etiquetas são “regraváveis”.
- Ativa – As etiquetas ativas são muito mais sofisticadas e caras e contam com uma bateria própria para transmitir seu sinal sobre uma distância razoável, além de permitir armazenamento em memória RAM capaz de guardar até 32 KB.
- Quais são as vantagens da RFID?
- Permite o rastreamento de itens;
- Controla as mercadorias em estoque;
- Possibilita o monitoramento de ambientes;
- Auxilia o funcionamento de sistemas antifurto;
- Realiza o controle de acesso em locais restritos;
- Contribui para sistemas de prevenção a falsificação.
- Aplicações
- Controle de Passagem: A tecnologia de controle de passagem pode ser usada tanto em postos de pedágio e estacionamento, como em controle de produtos em esteiras. Basta o objeto atravessar um sensor que capta sua identificação e de acordo com a demanda aciona (via programação) as ações necessárias.
- Controle de Estoque: Essa tecnologia já é utilizada em empresas médio e grande porte, principalmente quando se trata de grandes estoques de produtos, onde o controle deve ser atualizado rapidamente. Se o produto possui uma etiqueta RFID, com sensores nas prateleiras e/ou sessões do estoque, facilmente será identificado quando houver entrada e saída de estoque.
- Rastreamento: O uso de RFID para rastreamento já é utilizado por empresas que precisam de controle e logística de caminhões em seus pátios. Por exemplo, um caminhão quando faz carga e descarga, passa por várias etapas dentro de uma empresa, quando implantada uma etiqueta RF em seu pára-brisa, o caminhão passa pelos leitores e disponibiliza sua localização para o controle, possibilitando ao controlador saber se o próximo caminhão já pode ir para a pesagem. Outra forma de rastreamento que está sendo utilizada é para inibir assaltos a cargas, as empresas implantam o sistema de RFID nas cargas para facilitar a sua localização.
- Identificação: A tendência é que RFID sejam utilizados também para identificação biométrica, com a etiqueta RF em passaportes, documentos de identidade. Assim o detalhamento e as informações do indivíduo podem ser mais precisas, dispensando o uso de vários documentos. Essa tecnologia também está sendo estudada para ser utilizada em humanos, eliminando a documentação impressa, porém há muita controvérsia a respeito disto, pelo fato de controle governamental e privado sobre a população.
- Controle de Acesso: Hoje a Insoft4 já utiliza da tecnologia em seu sistema de controle de acesso de pessoas, através dos crachás de identificação por aproximação (Mifare) e o controle de acesso de veículos, no qual a etiqueta tag é instalada no veículo autorizado, que ao se aproximar do portão é reconhecido pelo leitor que aciona a cancela de forma automática, liberando a sua passagem. Funciona de forma semelhante ao sistema utilizado em pedágios (o Sem Parar).
- Obstáculos ao uso da RFID
- Baterias de baixo rendimento: Outro problema é a vida útil de uma bateria para etiquetas ativas de RFID, que ainda é muito curta, o que geraria um certo transtorno ao invés de comodidade, pois ela precisaria ser reposta em pouco tempo. Além disso, isso impede também o desenvolvimento de processos mais elaborados utilizando a RFID, o que demandaria ainda mais energia de seus dispositivos.
- Preço: Apesar de esta tecnologia vir se consolidando ao longo dos anos, ainda existem vários empecilhos para sua implantação em larga escala.Talvez o principal dele seja o preço, afinal para usá-lo serão necessários vários outros equipamentos e isso, para produtos de baixo custo (e baixo retorno financeiro), acaba não sendo a melhor alternativa.
- Segurança: Além disso, existe também o problema com a segurança, pois ainda não foi desenvolvido nenhum sistema à prova de interceptações. Mesmo as etiquetas passivas, que possuem alcance de apenas alguns metros, ainda se encontram vulneráveis a leituras indevidas de dados, o que pode causar vários danos.Pensando em uma situação em que você carregue seus dados como senhas de cartões, números de documentos e tudo mais, em um dispositivo presente em sua roupa, em seu celular ou em sua mão, a possibilidade de roubo de informações torna-se ainda maior e mais perigosa.Contra isso alguns estudos vêm sendo realizados e sistemas de criptografia de dados, implementação de códigos e também dispositivos metálicos como “embalagem” das etiquetas têm sido apontados como itens para garantir a segurança e a privacidade do RFID.
- Referências bibliográficas
- https://www.canalti.com.br/redes-de-computadores/rfid-o-que-e-como-funciona-utilizacao/
- https://www.tecmundo.com.br/tendencias/2601-como-funciona-a-rfid-.htm
- https://www.bloglogistica.com.br/tecnologia/tecnologia-rfid-o-que-e-e-como-se-aplica-na-area-logistica/
- http://insoft4aps.com.br/noticia/O-que-e-RFID-e-para-que-serve
Roteador
SaaS
Scrum
- Visão Geral:
- Scrum é uma metodologia ágil para gestão e planejamento de projetos de software.
- No Scrum, os projetos são divididos em ciclos (geralmente de 2 a 4 semanas) chamados de Sprints. O Sprint representa um Time Box dentro do qual um conjunto de atividades deve ser executado. Metodologias ágeis de desenvolvimento de software são iterativas, ou seja, o trabalho é dividido em iterações, que são chamadas de Sprints no caso do Scrum.
- As funcionalidades a serem implementadas em um projeto são mantidas em uma lista que é conhecida como Product Backlog. No início de cada Sprint, faz-se um Sprint Planning Meeting, ou seja, uma reunião de planejamento na qual o Product Owner prioriza os itens do Product Backlog e a equipe seleciona as atividades que ela será capaz de implementar durante o Sprint que se inicia. As tarefas alocadas em um Sprint são transferidas do Product Backlog para o Sprint Backlog.
- A cada dia de uma Sprint, a equipe faz uma breve reunião (normalmente de manhã), chamada Daily Scrum. O objetivo é disseminar conhecimento sobre o que foi feito no dia anterior, identificar impedimentos e priorizar o trabalho do dia que se inicia.
- Ao final de um Sprint, a equipe apresenta as funcionalidades implementadas em uma Sprint Review Meeting. Finalmente, faz-se uma Sprint Retrospective e a equipe parte para o planejamento do próximo Sprint. Assim reinicia-se o ciclo. Veja a ilustração abaixo:

- Práticas fundamentais:
- Scrum é fundamentado nas teorias empíricas de controle de processo, que afirmam que o conhecimento vem da experiência e da tomada de decisões baseadas no que é conhecido. Segue assim três pilares: a transparência, a inspeção e a adaptação.
- O framework Scrum tem como base as práticas descritas na figura abaixo, e detalhadas na sequência:
- Atividades básicas:
- Sprint Planning: O Product Backlog pode representar muitas semanas ou até meses de trabalho, o que é muito mais do que pode ser concluído em um único e curto sprint. Para determinar quais os subconjuntos de itens do Product Backlog mais importantes para construir no próximo Sprint, realiza-se o Sprint Planning (planejamento do sprint).
- Sprint: No Scrum, o trabalho é realizado em iterações ou ciclos de até um mês e com duração geralmente constante (timeboxed) chamados de Sprints. O trabalho realizado em cada sprint deve criar algo de valor tangível para o cliente ou usuário.
- Daily Scrum: é uma reunião diária com 15 minutos de duração, com objetivo de que a equipe de desenvolvimento possa analisar o progresso do dia anterior e planejar o trabalho a ser realizado nas próximas 24 horas, devendo ser realizada sempre no mesmo local, reduzindo a complexidade. Durante a reunião, cada membro do time de desenvolvimento deve responder às seguintes perguntas:
- O que foi feito desde a última reunião?
- O que será feito até a próxima reunião?
- O que está impedindo na conclusão do trabalho?
- Com estas respostas avalia-se o progresso em direção ao objetivo final. Pode-se também identificar e remover qualquer problema que possa impactar na conclusão das atividades do backlog.
- Sprint Review: o objetivo desta atividade é verificar e adaptar o produto que está sendo construído. Esta é uma reunião informal, e a apresentação do incremento destina-se a motivar e obter comentários e promover a colaboração.
- Sprint Retrospective: enquanto o objetivo do Sprint Review é verificar necessidades de adaptações no produto, o Sprint Retrospective tem como objetivo verificar necessidades de adaptações no processo de trabalho. Ocorre depois da Revisão da Sprint e antes da reunião de planejamento da próxima Sprint.
- Artefatos Principais:
- Product backlog: é uma lista de funcionalidades ou características que são necessárias no produto, sendo esses itens ordenados por prioridade. Um backlog do produto nunca está completo, evoluindo como produto em consequência de um melhor entendimento de seus requisitos.
- Sprint backlog: é uma lista que contém os itens que foram selecionados do backlog do produto para o desenvolvimento, juntamente com o plano de entrega e o objetivo da Sprint, ou seja, é o planejamento do que será entregue no próximo incremento do produto.
- Definition of Done: Documento que descreve quando e como uma parte do produto ou funcionalidade deve ser considerada concluída.
- Papéis e Responsabilidades:
- O Product Owner, ou simplesmente PO, representa o cliente, patrocinadores e/ou financiadores do projeto. Pode ser um representante do cliente dentro da empresa, ou um analista de negócio. É quem vai definir, gerenciar e priorizar os requisitos, gerenciar o ROI (Return Over Investment). O Product Owner trabalha como parte do time que realiza a entrega.
- O Scrum Master, ou simplesmente SM, representa a gestão do projeto, mas não no sentido de gestão tradicional. Na realidade, o SM funciona mais como um mediador e líder coach (em sentindo de coaching, como um técnico de time de futebol). O Scrum Master trabalha com e para o time.
- O Scrum team, ou equipe, é composto por indivíduos que estão comprometidos em realizar o trabalho proposto. Os times são cross-functional. Mas o que isso quer dizer? Nos métodos tradicionais existem papéis distintos, por exemplo, arquitetos, testadores, etc. Em um time Scrum, temos pessoas com habilidades de arquitetura que podem ter uma habilidade secundária para ajudar nos testes. Ou seja, colaboração é a palavra de ordem.
- Referências:
Sensores
- Conceito:
Os sensores são dispositivos que tem a função de detectar estímulos e interpretá-los, convertendo com eficiência em alguma resposta. Existem diversos tipos de sensores que respondem à estímulos diferentes, como ao calor, luz, movimento. Hoje em dia, esse tipo de tecnologia tem crescido consideravelmente e já abrange alguns setores da sociedade, tornando-se cada vez mais presente no nosso cotidiano. Um exemplo compatível com a realidade de todos são os leitores biométricos, que recolhem impressões digitais e fornecem em algum dispositivo uma resposta conciliável com o estímulo.
- Tipos e aplicações:
Existem inúmeros modelos de sensores no mercado e cada um apresenta uma função e propriedade específica. Por isso, é impossível citar aqui a maneira de funcionamento referente a todos os sensores individualmente. Entretanto, há alguns tipos que são mais presentes e se aplicam à nossa rotina. A título de exemplo, temos:
- Leitor de impressão digital do celular: Atualmente, quase todo smartphone dispõe da aplicação de leitura das digitais do seu usuário, seja para acessar algum aplicativo ou desbloquear o aparelho. É notável que as impressões digitais são únicas para cada indivíduo, o que possibilita uma maior segurança do dispositivo em que serão cadastradas. Para capturar a imagem digital, faz-se necessário um leitor que funciona como uma espécie de scanner, recolhendo as informações sobre a impressão e comparando-as com o padrão existente no sistema, levando o usuário ou não à ação desejada.

- Sensor óptico: Estes sensores, também conhecidos como fotoelétricos, usam a propagação da luz para o seu funcionamento. Em sua maioria, são divididos em dois componentes, que são: Uma unidade emissora responsável por emitir a luz e outra unidade receptora responsável por captar a luz emitida. Esse tipo de sensor possui várias funcionalidades, como em mouses de computador, leitor de código de barras, portas de garagem automáticas.

- Sensor elétrico: Os sensores elétricos são modelos de sensores que detectam variações numa grandeza elétrica, como aumento distorcivo da corrente, mudança brusca na tensão, e emitem um sinal para alterar as propriedades do circuito. Apesar desse tipo de aparelho não ser conhecido por múltiplas pessoas, o fato é que ele é presente na maioria dos locais que apresentam energia elétrica, por isso sua tamanha importância.

- Conclusão:
Portanto, percebe-se a relevância desse tipo de tecnologia na nossa sociedade, que engloba inúmeros meios produtivos, pessoas e dispositivos.
- Referências Bibliográficas:
https://www.mundodaeletrica.com.br/o-que-sao-sensores-e-quais-as-suas-aplicacoes/
https://www.dicio.com.br/sensor/
Sistema embarcado
- Introdução
Sistemas embarcados revolucionam o mundo continuamente melhorando a vida das pessoas. Basta olhar ao redor e perceber que eles estão em quase todos os lugares e que suas aplicações impulsionaram o desenvolvimento tecnológico de todas as áreas de conhecimento humano. Mas o que um sistema embarcado consegue fazer?
Um sistema embarcado salva vidas em marcapassos, garante a segurança dos transportes em computadores aviônicos e freios ABS, também aproxima as pessoas através de satélites e equipamentos de telecom, agrega conforto ao dia a dia com impressoras, TVs e players de mídia, e, ainda deixa a nossa vida mais divertida com os consoles de games. Sistema embarcado também é aplicado em sistemas de rede elétrica, em sistemas bélicos, em reatores nucleares, enfim, eles estão presentes em quase todos os eletrônicos.
- O que é ?
O sistema embarcado, também chamado de sistema embutido, é um sistema microprocessado em que um computador está anexado ao sistema que ele controla. Um sistema embarcado pode realizar um conjunto de tarefas que foram predefinidas. O sistema é usado para tarefas específicas, e assim, através de engenharia é possível otimizar um determinado produto e diminuir o tamanho, bem como os recursos computacionais e o seu valor final. Em geral tais sistemas não podem ter sua funcionalidade alterada durante o uso. Caso queira-se modificar o propósito é necessário reprogramar todo o sistema.
- Aplicações
Os sistemas embarcados estão por toda a nossa volta, e por essa razão, não nos damos conta de sua capacidade computacional, já que estamos tão envolvidos com tais mecanismos. Sistemas embarcados operam em máquinas que podem trabalhar por vários anos sem parar, e que ainda, em alguns casos, possuem a capacidade de autocorreção. Um excelente exemplo de itens que usam sistemas embarcados são os famosos smartphones, que desempenham funções específicas, e que contam com mecanismos mais limitados que os computadores. Confira baixo uma lista com alguns exemplos que recebem a aplicação de sistemas embarcados: • Urna eletrônica;
• Videogames;
• Calculadoras;
• Impressoras;
• Alguns eletrodomésticos;
• Aparelhos celulares;
• Equipamentos hospitalares;
• Em veículos;
• Roteadores.
- Fontes:
https://www.embarcados.com.br/sistema-embarcado/
https://www.oficinadanet.com.br/post/13538-o-que-sao-sistemas-embarcados
SO
SQL
- Conceito
É uma linguagem que surgiu na década de 70, e significa "Structured Query Linguage" em português "Linguagem de Consulta Estruturada" , usada para se comunicar com o banco de dados, com o foco ao modelo relacional. O modelo relacional é um modelo de dados representativo, adequado a ser o modelo subjacente de um Sistema Gerenciador de Banco de Dados , que se baseia no princípio de que todos os dados estão armazenados em tabelas.
- Pra que serve?
Como sendo uma linguagem padrão para o gerenciamento de banco de dados, suas instruções são usadas para executar tarefas como criar, deletar, consultar e atualizar o banco de dados, além de inserir dados e manipula-los. Uma de suas operações mais conhecidas é o CRUD – Create, Read, Update e Delete que nada mais é do que a composição das operações básicas que uma aplicação realiza em um banco de dados, criação, leitura, atualização e exclusão de dados.
- Como funciona?
Após a criação do banco de dados, os dados serão armazenados em campos dentro de tabelas , imagine que você esta guardando pastas(campos) dentro de gavetas(tabelas) em uma cômoda(banco de dados), ao criar cada tabela você precisa definir quantos campos terão e o tipo de dado que cada campo irá guardar, além de estabelecer uma chave primária que representará a tabela, e/ou uma chave secundária para se relacionar com outras tabelas.
- Referência bibliográficas
Speech Recognition
- "O que é?"
- Trata-se de uma tecnologia que possibilita que dispositivos respondam a ditados e/ou comandos de voz.
- "Como funciona"
- Para que um sistema possa interpretar a fala humana, deve haver, com o auxílio de um microfone, a tradução das vibrações da voz de uma pessoa em sinais elétricos em forma de ondas. Esse sinal, então, é convertido pelo hardware do sistema -- e.g., a placa de áudio de um computador -- em um sinal digital, o qual será avalizado pelo programa de reconhecimento de voz para isolar os fonemas, que são os blocos básicos da constituição da fala. Os fonemas são, em seguida, recombinados em palavras. No entanto, como há várias palavras homófonas, o programa precisa analisar o contexto para identificar a palavra correta. Nesse caso, os programas costumam estabelecer o contexto por meio de análises de trigramas, ou seja, a partir de uma base de dados contendo grupos frequentes de três palavras, considerando as probabilidades de duas palavras serem seguidas por uma terceira palavra. Por exemplo, se uma pessoa fala, em inglês, "who am", a próxima palavra será, considerando a probabilidade do contexto, o pronome "I", e não a palavra "eye", muito embora se trate de um caso de homofonia. Mesmo assim, em alguns casos é necessária intervenção humana para a correção de erros.
- Sistemas mais recentes têm apostado em aprendizagem profunda ("deep learning"), sobretudo em redes neurais, para ganhar flexibilidade em relação a essas regras de probabilidade. Um exemplo, é a Google Google Cloud Speech-to-Text, que converte áudio em texto aplicando modelos de redes neurais avançados em uma API que reconhece mais de 120 idiomas e variantes.
- Programas que reconhecem algumas palavras isoladas, como os sistemas de navegação por voz dos celulares, geralmente funcionam para quase todo tipo de usuário. No entanto, em se tratando de fala contínua, como em casos de ditados, deve haver um treinamento do programa para reconhecer os padrões de fala de cada indivíduo, geralmente a partir da leitura em voz alta de alguns espécimes de texto.
- Os principais obstáculos para a qualidade de um sistema de reconhecimento de voz são as linguísticas, individuais e de canal. A variabilidade linguística se refere aos efeitos da fonética, fonologia, sintaxe, semântica e discurso na fala. A variabilidade individual refere-se às variações entre indivíduos e até mesmo em um único indivíduo, sobretudo no que diz respeito aos efeitos da coarticulação, i.e., efeitos dos sons vizinhos na realização acústica de um fonemas devido à continuidade e restrições motoras sobre o aparelho articulatório humano. Por sua vez, a variabilidade de canal se refere aos efeitos dos sons de fundo e do canal de transmissão (e.g., telefone, microfone). Todas essas variabilidades tendem a prejudicar a mensagem intencionada com algum grau de incerteza, a qual precisa ser superada pelo processo d reconhecimento.
- "Aplicações"
- O reconhecimento de voz permite o controle, sem as mãos, de diversos dispositivos e equipamentos, o que é fundamental para pessoas com deficiências; fornece entrada para tradução automática; e viabiliza ditado de texto. Dentre as primeiras aplicações de reconhecimento de voz, citam-se os sistemas telefônicos e os softwares de ditado para fins médicas. Essa tecnologia é comumente utilizada para ditados, buscas em bancos de dados e comandos a sistemas computacionais, especialmente em profissões ou áreas que se baseiam em termos especializados. Além disso, funciona como assistente pessoal em veículos e smartphones, como é o caso da Siri, da Apple.
- "Referências"
- GOOGLE. Cloud Speech-to-text. Disponível em: https://cloud.google.com/speech-to-text/?&utm_source=google&utm_medium=cpc&utm_campaign=latam-BR-all-pt-dr-skws-all-all-trial-b-dr-1003997-LUAC0009046&utm_content=text-ad-none-none-DEV_c-CRE_331159561915-ADGP_SKWS+%7C+Multi+~+Developers+%7C+Speech-Recognition-KWID_43700042069969651-kwd-321478451406-userloc_1001590&utm_term=KW_%2Bspeech%20%2Brecognition-ST_%2BSpeech+%2BRecognition&gclid=Cj0KCQjwh6XmBRDRARIsAKNInDEOONe7Ed_CiPKBdw5fshFxMEYu_sULakI3J3WkYZ7DDD0fT0nRDWEaAvm3EALw_wcB&gclsrc=aw.ds. Acesso em: 1 maio 2019.
- MAKHOUL, J.; SCHWARTZ, R. State of the art in continuous speech recognition. Proc Natl Acad Sci U S A, v. 92, n. 22, p. 9956-9963, 1995.
- TOLEDANO, D. T.; FERNÁNDEZ-GALLEGO, M. P.; LOZANO-DIEZ, A. Multi-resolution speech analysis for automatic speech recognition using deep neural networks: Experiments on TIMIT. PLoS ONE, v. 13, n. 10, p. e0205355, 2018.
- ZWASS, V. Speech recognition. In: Britannica Academic. Disponível em: https://academic-eb-britannica.ez34.periodicos.capes.gov.br/levels/collegiate/article/speech-recognition/126497. Acesso em: 1 maio 2019.
Firmware
- Conceito
O Firmware e um software de computador que vem junto com Hardware. Ele serve para controlar as configurações do Hardware especifico do dispositivo, funções de controle, monitoramento e manipulação de dados. O software do está presente dentro de um microchip instalado dentro Hardware do dispositivo. Sistemas que possuem firmware podem ser encontrados em:
- Semáforos
- Aparelhos Celulares
- Bios, UEFI e EFI
- Placas de vídeos
- Referência bibliográficas
UML
- O que é UML - Unified Modeling Language ?
- A Linguagem de modelagem unificada (UML) foi criada para estabelecer uma linguagem de modelagem visual comum, semanticamente e sintaticamente rica, para arquitetura, design e implementação de sistemas de software complexos, tanto estruturalmente quanto para comportamentos. Além do desenvolvimento de software, a UML tem aplicações em fluxos do processo na fabricação.
- A UML não é uma linguagem de programação, mas existem ferramentas que podem ser usadas para gerar código em várias linguagens por meio de diagramas UML. Tem uma relação direta com a análise e o design orientados a objetos. É uma combinação de várias notações orientadas a objetos: design orientado a objetos, técnica de modelagem de objetos e engenharia de software orientada a objetos. Representa as melhores práticas para desenvolver e documentar aspectos diferentes da modelagem de software e sistemas de negócios.
- Conceitos de Modelagem
- O desenvolvimento de sistemas centra-se em três modelos gerais e diferentes do sistema:
- Funcional: são diagramas de caso de uso, e descrevem a funcionalidade do sistema a partir do ponto de vista do usuário.
- Objeto: são diagramas de classes, e descrevem a estrutura do sistema em termos de objetos, atributos, associações e operações.
- Dinâmico: diagramas de interação, diagramas de máquinas de estados e diagramas de atividade, e são usados para descrever o comportamento interno do sistema.
- O desenvolvimento de sistemas centra-se em três modelos gerais e diferentes do sistema:
- Conceitos orientados a objetos
- Os objetos em UML são entidades do mundo real que existem ao nosso redor.
- Alguns conceitos fundamentais de um mundo orientado a objetos são :
- Objetos: Representam uma entidade e um componente básico essencial.
- Classe: Modelo de um objeto.
- Abstração: Comportamento de uma entidade do mundo real.
- Encapsulamento: Mecanismo de vincular os dados e escondê-los do mundo exterior.
- Herança: Mecanismo de criar novas classes a partir de uma existente.
- Polimorfismo: Define o mecanismo em diferentes formas.
- Tipos de Diagramas UML
- Usa-se diferentes elementos associando-os de maneiras diferentes formando diagramas que representam aspectos estruturais de um sistema, além de diagramas comportamentais que registram os aspectos dinâmicos de um sistema.
- Diagramas estruturais:
- Diagrama de classes: É o diagrama UML mais usado, e a principal base de qualquer solução orientada a objetos. Classes dentro de um sistema, atributos e operações, e a relação entre cada classe. Classes são agrupadas para criar diagramas de classes quando há uma diagramação de grandes sistemas.
- Diagrama de componentes: Exibe a relação estrutural de elementos do sistema de software, na maioria das vezes utilizado quando se trabalha com sistemas complexos com múltiplos componentes. Componentes se comunicam por meio de interfaces.
- Diagrama de estrutura composta: Diagramas de estrutura composta são utilizados para mostrar a estrutura interna de uma classe.
- Diagrama de implementação: Ilustra o hardware do sistema e seu software. É útil quando uma solução de software é implantada em diversas máquinas com configurações únicas.
- Diagrama de objetos: Mostra a relação entre objetos usando exemplos do mundo real e retrata um sistema em um determinado momento. Como os dados estão disponíveis dentro de objetos, eles podem ser utilizados para esclarecer as relações entre objetos.
- Diagrama de pacotes: Existem dois tipos especiais de dependências definidas entre pacotes: a importação do pacote e a mesclagem do pacote. Para revelar a arquitetura, os pacotes representam os diferentes níveis de um sistema. Dependências de pacotes podem ser marcadas para mostrar o mecanismo de comunicação entre os níveis.
- Diagramas comportamentais:
- Diagramas de atividade: Fluxos de trabalho de negócios ou operacionais representados graficamente para exibir a atividade de qualquer parte ou componente do sistema. Diagramas de atividade são usados como alternativa aos diagramas de máquina de estados.
- Diagrama de máquina de estados: Semelhante a diagramas de atividade, eles descrevem o comportamento de objetos que se comportam de maneiras diferentes em seu estado atual.
- Diagrama de caso de uso: Representa uma determinada funcionalidade de um sistema, e foi criado para ilustrar a forma como as funcionalidades se relacionam e seus controladores internos e externos (atores).
- Diagrama de integração:
- Diagrama de sequência: Mostra como objetos interagem entre si, e a ordem de ocorrência. Representam interações para um determinado cenário.
- Diagrama da visão geral da interação: Há sete tipos de diagramas de interação, e este diagrama exibe a sequência em que eles atuam.
- Diagrama de tempo: Assim como os diagramas de sequência, representa o comportamento de objetos em um determinado período de tempo. Se houver um único objeto, o diagrama é simples. Se houver mais de um objeto, as interações dos objetos são exibidas durante este período de tempo determinado.
- Diagrama de comunicação: Semelhante a diagramas de sequência, no entanto foca mensagens transmitidas entre objetos. A mesma informação pode ser representada usando um diagrama de sequência e outros objetos.
- Diagramas estruturais:
- Usa-se diferentes elementos associando-os de maneiras diferentes formando diagramas que representam aspectos estruturais de um sistema, além de diagramas comportamentais que registram os aspectos dinâmicos de um sistema.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Referencias
- https://books.google.com.br/books?hl=pt-BR&lr=&id=elvjBwAAQBAJ&oi=fnd&pg=PT4&dq=UML&ots=xUTnPNrVyC&sig=eZHvzL-UyGTJTZLNFSF_uqFuPM8#v=onepage&q=UML&f=false
- https://www.uml.org/what-is-uml.htm
- https://books.google.com.br/books?hl=pt-BR&lr=&id=ddWqxcDKGF8C&oi=fnd&pg=PR13&dq=UML&ots=feAMpf8NPP&sig=INxlV5T1Rd0shXRc9wvpBtMqj_U#v=onepage&q=UML&f=false
- https://books.google.com.br/books?hl=pt-BR&lr=&id=xxoXcuh0oS0C&oi=fnd&pg=PR8&dq=UML&ots=ut3N9ClP9x&sig=rRZz50MynVyeg9cwebVffE7RBs8#v=onepage&q=UML&f=false
Virtualização
Web
- Conceito
- Web ou world wide web são os termos designados para representar documentos em formato de links que quando executados na internet geram uma resposta apropriada ao usuário, por exemplo abrir uma página.
Funcionamento
- Através de um navegador os links são lidos utilizando endereços de IP e portas para encontrar o local de hospedagem da página desejada, após encontrar a página é feita a conexão entre os dois pontos por meio da internet para que a ação de abrir página seja executada.
- Referências