Provas
- Datas
- 1a. Prova - 25,0 pts: 16/01/2014
- 2a. Prova - 25,0 pts: 06/03/2014
Notas
| Nome | 1a. prova | 2a. prova | Modelo Hierárquico | Comandos SQL | Novas Tecnologias |
|---|---|---|---|---|---|
| ................................ Pontuação | 25,0 | 25,0 | 10,0 | 25,0 | 15,0 |
| Caetano Alcantara Borges - 9169 9931 | 10,5 | 20,1 | 7,5 | 22,0 | 14,0 |
| Fernando Beletti - 9193 5335 | 14,0 | 21,0 | 8,0 | 24,0 | 12,0 |
| Hiago Araújo Silva - 9993-5786 | 16,0 | 11,2 | 8,0 | 21,5 | 13,0 |
| Igor Eduardo Leandro Alvarenga - 9103-7791 | 14,5 | 17,3 | 9,0 | 23,5 | 13,0 |
| Lucas Ramos Cardoso - 9276-0122 | 11,5 | 14,0 | 7,5 | 20,5 | 12,0 |
| Yassusshi Miguel Ávila Okada - 9178 2239 | 12,0 | 13,5 | 8,5 | 21,5 | 11,0 |
Trabalhos
1o. Trabalho - 10,0 pontos
- Criação de Banco de Dados Hierárquico com as funções CRUD
- Fernando: Conceito
- Hiago: Estrutura
- Igor: Inclusão
- Yassushi: Exclusão
- Lucas: Pesquisa
- Caetano: Alteração
Código Modelo Hierárquico
2o. Trabalho - 25,0 pontos
- Implementação de um Banco de Dados usando o SGBD abaixo:
- MySQL:
- Fernando: SMTC
- MySQL:

- Considerações:
- O diagrama é bastante simples, uma vez que o sistema é fortemente baseado em relatórios de fluxos e tempo de semáforos abertos. Estes dados são calculados a partir dos dados dos ciclos (tempos em que o semáforo fica aberto) e não é interessante guardá-los, já que devido à grande "rotatividade" do sistema, a todo momento estes relatórios são atualizados.
- Por exemplo, o tempo que um semáforo fica fechado não precisa ser salvo, já que basta fazer o complemento do tempo em que ele fica aberto (foco do sistema).
- Igor: Bus Route


- Oracle:
- Hiago: Kodificando
- Hiago: Kodificando
- Oracle:

- Lucas: Jarvas
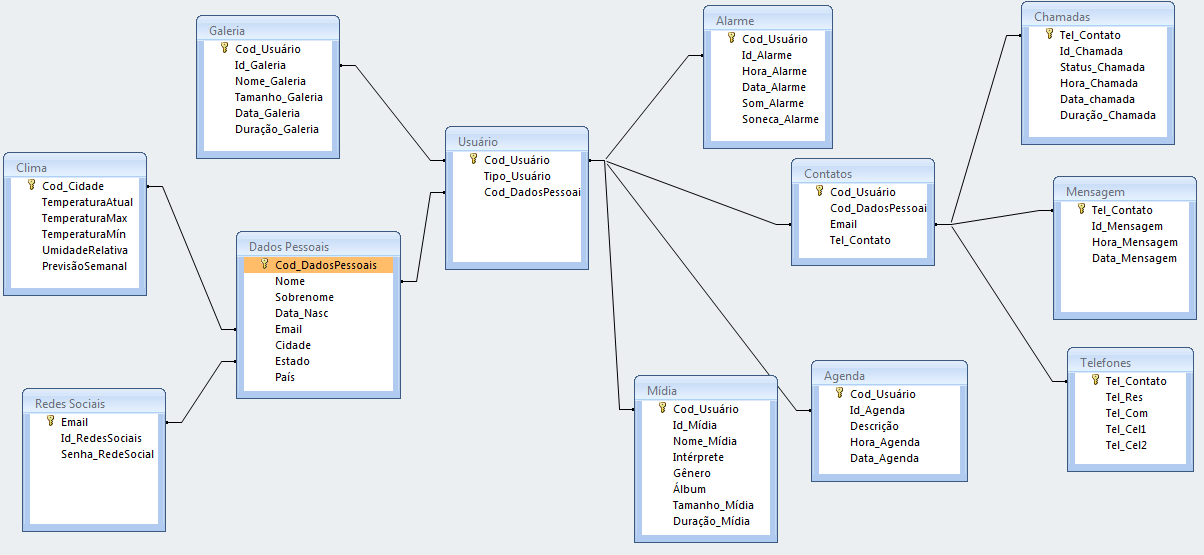

- PostgreSQL:
- Caetano: Game 2D
- PostgreSQL:

- Considerações:
- Em Save, o checkpoint é o local onde o usuário salvou o jogo
- Em Persongem, Item, Inimigo, o atributo imagem seria a imagem deles no jogo
- Em Item, o atributo Tipo_item, se refere se é uma arma, escudo, armadura, etc.
- Loot é onde informa os itens que o inimigo deixa ao personagem ao ser derrotado
- Em Inimigo, o atributo Experiencia_inimigo é a quantidade de experiencia que o inimigo dá ao personagem ao ser derrotado
- Com conexões e links se guarda as formas como os mapas estão ligados entre si
- Considerações:
- Considerações finais
- A forma de guardar todas as informações sobre o jogo, podem variar bastante de um jogo específico para outro. Esse DER apresenta uma forma mais geral, seguindo informações dadas pelo grupo desenvolvedor do projeto game 2D. Assim sendo, antes da implementação e principalmente da população do banco de dados, deve-se discutir se esse diagrama satisfaz o projeto com o grupo desenvolvedor.
- Considerações finais
- Yassushi: Salao de beleza

- Procedimentos:
- Avaliar 5W2H -> Ok
- Incluir Comentários -> Ok
- Desenhar DER - Diagrama Entidade Relacionamento => 30/01
- Implementar comandos do SQL => 10/02
- DDL
- Usar PostgreSQL, MySQL ou Oracle
- Criar todas as tabelas necessárias
- Especificar as chaves primárias (Primary Key)
- Aplicar os limites de cada campo (Constraints)
- Criar os índices mais relevantes (Index)
- Criar as views mais úteis (Views)
- DML
- DCL
- DDL
3o. Trabalho - 15,0 pontos
- Pesquisa sobre novas tecnologias
Data Mining
- Yassushi: 10/02
Data mining ou em português mineração de dados, consiste em uma funcionalidade que agrega e organiza dados, encontrando neles padrões, associações, mudanças e anomalias relevantes. Ou melhor, é uma análise projetada com o objetivo de vasculhar uma grande quantidade de dados armazenados em depósito de dados, banco de dados ou outros repositórios de informação. Na maioria das vezes, são dados relacionados a negócios, empresas, mercado e pesquisas científicas.
O data mining pode ser divido em algumas etapas básicas que são: exploração, construção de modelo, definição de padrão e validação e verificação. E o resultado final da sua utilização pode ser exibido através de regras, hipóteses, árvores de decisão, etc. Uma mineração de dados bem executada deve cumprir tarefas como: detecção de anomalias, aprendizagem da regra de associação (modelo de dependência), clustering (agrupamento), classificação, regressão e sumarização. O processo de data mining costuma ocorrer utilizando dados contidos dentro do data warehouse.
O conceito de data mining é muitas vezes associado à extração de informação relativa ao comportamento de pessoas. Por esse motivo, em algumas situações, a mineração de dados levanta aspectos legais e questões relativas à privacidade e ética. Apesar disso, muitas pessoas afirmam que a mineração de dados é eticamente neutra, pois não apresenta implicações éticas. Dentre as etapas mais aprofundadas do Data Mining, podemos elucidar as seguintes:
Análise do problema: O processo de análise inicia a partir de um objetivo de busca, seguindo um determinado conhecimento; o principal objetivo é a possibilidade de selecionar os dados e definir as técnicas utilizadas na análise.
Preparação dos Dados: A preparação consiste em fases internas de coletânea de dados, avaliação, consolidação e limpeza, seleção dos dados e transformação.
-Coletânea de dados: Dados provindos de diversas fontes internas ou externas, como por exemplo de cartão de crédito;
-Avaliação: Exame sobre os dados colhidos com o objetivo de identificar características do modelo da cada informação.
-Consolidação e limpeza: Construção de base de dados a partir de correções de erros, remoção de registros e inserção de valores comuns em campos vazios.
-Seleção de dados: É a seleção de dados específicos para cada modelo de dado, como a seleção de variáveis em colunas ou dependentes.
-Transformação: Ferramenta escolhida para redirecionar a apresentação dos dados.
Modelagem: Definição de tarefas e técnicas utilizadas sobre a ação de cada algoritmo, etapa que gera um modelo a ser analisado posteriormente.
Análise e validação de resultados: Considerando que um modelo válido nem sempre é um modelo correto, visa detectar o que há de implícito num modelo, e o que nele é mais peculiar na precisão de uma informação.
Exemplos Aplicação:
Wal- Mart
Embora recente, a história do data mining já tem casos bem conhecidos. O mais divulgado é o da cadeia americana Wal-Mart, que identificou um hábito curioso dos consumidores. Há cinco anos, ao procurar eventuais relações entre o volume de vendas e os dias da semana, o software de data mining apontou que, às Sextas-feiras, as vendas de cervejas cresciam na mesma proporção que as de fraldas. Crianças bebendo cerveja? Não, uma investigação mais detalhada revelou que, ao comprar fraldas para seus bebês, os pais aproveitavam para abastecer o estoque de cerveja para o final de semana.
Bank of America
Há quem consiga detectar fraudes, cortar gastos ou aumentar a receita da empresa. O Bank of America usou essas técnicas para selecionar entre seus 36 milhões de clientes aqueles com menor risco de dar calote num empréstimo. A partir desses relatórios, enviou cartas oferecendo linhas de crédito para os correntistas cujos filhos tivessem entre 18 e 21 anos e, portanto, precisassem de dinheiro para ajudar os filhos a comprar o próprio carro, uma casa ou arcar com os gastos da faculdade. Resultado: em três anos, o banco lucrou 30 milhões de dólares.
Telecomunicações
Atualmente, em telecomunicações, existe uma explosão nos crimes contra a telefonia celular, dentre os quais, a clonagem. Técnicas de data mining podem ser utilizadas para detectar hábitos dos usuários de celulares. Quando um telefonema for feito e considerado pelo sistema como uma excessão, o programa faz uma chamada para confirmar se foi ou não uma tentativa de fraude.
Administração em Alto Nível
Depois do final da segunda guerra mundial a Pesquisa Operacional (P0) apareceu como ferramenta fundamental para a vitória das tropas contra as potências do eixo. Com a pesquisa operacional foi possível resolver matematicamente o problema de alocação ótima de recursos e isto vem sendo utilizado com grande sucesso em altos níveis de decisão até o presente momento. Cerca de cinquenta anos depois, apareceu o data mining.Suas potencialidades estão longe de serem imaginadas e não seria ousado esperar que no mundo globalizado possa vir a dar seus frutos como a PO deu no passado.
Medicina
Atualmente as técnicas de data mining são pouco usadas em medicina. No momento, o ponto que está emperrando o uso de data mining é o fato de que data mining sendo uma nova concepção dirigida para pesquisa ainda é quase completamente desconhecida da comunidade médica. Ora, se existem dados clínicos abundantes, estes dados são frequentemente adequados a um estudo de data mining por não conterem dados que aparentemente são inúteis mas que são exatamente os que o pesquisador de data mining procura.
Ferramentas
RapidMiner:
Ambiente open-source desenvolvido em Java que permite explorar os dados de diversas maneiras por meio de operadores (sejam eles para pré-processamento, aprendizado, validação, etc) organizados em uma estrutura de árvore. O interessante é que após pegar o básico do programa torna-se fácil realizar os experimentos, já que apenas precisa-se escolher os operadores e combiná-los da forma que quiser. Além disso, as funções do Weka são integradas ao software.
Video de introdução ao software: http://www.youtube.com/watch?v=Cf5aNBvWYK0
MOA Massive Online Analysis:
Em português, Análise Massiva em Tempo Real, o qual utiliza técnicas de aprendizado incremental para criar modelos preditivos através de fluxos de dados, possuindo ainda integração bi-direcional com o Weka, isto é, o Weka consegue manipular dados e algoritmos do MOA, e vice-vesa.
WEKA:
Software livre em java para mineração de dados. O Weka tem como objectivo agregar algoritmos provenientes de diferentes abordagens/paradigmas na sub-área da inteligência artificial dedicada ao estudo da aprendizagem por parte de máquinas.
Essa sub-área pretende desenvolver algoritmos e técnicas que permitam a um computador "aprender" (no sentido de obter novo conhecimento) quer indutiva quer dedutivamente.
O Weka procede à análise computacional e estatística dos dados fornecidos recorrendo a técnicas de data-minning tentando, indutivamente, a partir dos padrões encontrados gerar hipóteses para soluções e no extremos inclusive teorias sobre os dados em questão.
Enterprise Miner:
Ferramenta de data mining do SAS
IlliMine:
Projeto de mineração de dados escrito em C++.
InfoCodex:
Aplicação de mineração de dados com uma base de dados linguística.
KDB200:
Uma ferramenta livre em C++ que integra acesso à bases de dados, pre-processamento, técnicas de transformação e um vasto escopo de algoritmos de mineração de dados.
KXEN:
Ferramenta de mineração de dados comercial, utiliza conceitos do Profesor Vladimir Vapnik como Minimização de Risco Estruturada (Structured Risk Minimization ou SRM) e outros.
KNIME:
Plataforma de mineração de dados aberta que implementa o paradigma de pipelining de dados. Baseada no eclipse
Lingpipe:
API em Java para mineração em textos distribuída com código-fonte.
MDR:
Ferramenta livre em Java para detecção de interações entre atributos utilizando o método da multifactor dimensionality reduction (MDR).
Orange Tookit:
Ferramenta livre em Python para mineração de dados e aprendizado de máquina.
Pimiento:
Um ambiente para mineração em textos baseado em Java.
Tanagra:
Software livre de mineração de dados e estatística.
Cortex Intelligence:
Sistema de PLN para mineração de textos aplicado à Inteligência Competitiva
Referências
http://pt.wikipedia.org/wiki/Weka, http://moa.cms.waikato.ac.nz/, http://www.coc.ufrj.br/index.php/component/docman/doc_view/1298-marcelo-beckmann-mestrado, http://www.infoescola.com/informatica/data-mining/, http://www.dct.ufms.br/~mzanusso/Data_Mining.htm, http://www.guiafar.com.br/portal/index.php/pt/artigos/tecnologia-da-informacao/159-data-mining-mineracao-de-dados?start=4, http://lffranca.wordpress.com/2009/08/21/rapidminer/, http://rapidminer.com/learning/getting-started/.
DataWarehouse
- Lucas: 13/02
O Data Warehouse surgiu principalmente devido às dificuldades que muitas empresas começaram a enfrentar devido a quantidade de dados que suas aplicações estavam gerando e à dificuldade de reunir estes dados de maneira integrada para uma análise mais eficiente. A ideia, então, foi armazenar em um único local, somente os dados considerados uteis no momento de tomar decisões.Segundo W.H.Inmon, considerado um pioneiro no tema, um data warehouse é uma coleção de dados orientada por assuntos, integrada, variante no tempo, que tem por objetivo dar suporte aos processos de tomada de decisão.
Um exemplo que podemos citar são as empresas de transporte aéreo, que através da tecnologia Data Warehouse, podem obter a informação de qual mês do ano há maior procura de voos para São Paulo, ou então, para quais locais os jovens com menos de vinte e cinco anos então viajando através dos meios aéreos.
O data warehouse é um banco de dados contendo dados extraídos do ambiente de produção da empresa, que foram selecionados e depurados, tendo sido otimizados para processamento de consulta e não para processamento de transações. Em geral, um data warehouse requer a consolidação de outros recursos de dados além dos armazenados em base de dados relacionais, incluindo informações provenientes de planilhas eletrônicas, documentos textuais, etc.
De acordo com Richard Hackathorn (outro pioneiro no tema), o objetivo de um data warehouse é fornecer uma "imagem única da realidade do negócio". De uma forma geral, sistemas de data warehouse compreendem um conjunto de programas que extraem dados do ambiente de dados operacionais da empresa, um banco de dados que os mantém, e sistemas que fornecem estes dados aos seus usuários.
Sistemas de Data Warehouse revitalizam os sistemas da empresa, pois:
• Permitem que sistemas mais antigos continuem em operação; • Consolidam dados inconsistentes dos sistemas mais antigos em conjuntos coerentes; • Extraem benefícios de novas informações oriundas das operações correntes; • Provém ambiente para o planejamento e arquitetura de novos sistemas de cunho operacional.
Como se vê, existem diferentes visões do que seria um data warehouse: uma arquitetura, um conjunto de dados semanticamente consistente com o objetivo de atender diferentes necessidades de acesso a dados e extração de relatórios, ou ainda, um processo em constante evolução, que utiliza dados de diversas fontes heterogêneas para dar suporte a consultas ad-hoc, relatórios analíticos e à tomada de decisão.
Ferramentas
O Hive é um framework para soluções de Data Warehousing, que executa no ambiente do Hadoop, construído inicialmente pelo time de desenvolvimento do Facebook em 2007. Ele nasceu a partir da necessidade de gerenciar, analisar e aprender sobre o comportamento dos usuários a partir dos imensos volumes de dados gerados a cada dia no Facebook. A escolha pelo Hadoop foi incentivada pelo baixo custo, escalabilidade e evitar a dependência sobre custos de licenças e manutenção anual que são comuns nos bancos de dados do mercado
Hive utiliza uma linguagem chamada HiveQL (Hive Query Language) , que transforma as sentenças SQL em Jobs MapReduce executados no cluster Hadoop.
Os comados existentes no SQL tais como create table, select, describe, drop table, etc existem no Hive, mas tem diferenças tal como a clausula ROW FORMAT do create table. Para popular tabelas pode ser utilizado o comando LOAD DATA , que obtém a entrada de dados e carrega no warehouse do Hive.
Podem ser utilizados agregadores como Max, SUM, Count, etc que necessitam da clausula GROUP BY, tal como no SQL.
Para acessar os dados podem ser utilizadas a própria interface de comandos, drivers JDBC, drivers ODBC e o Hive Thrift Client (para C++, Python, Ruby, etc). Possibilita acessar dados que estejam no sistema de arquivos HDFS, em outros sistemas de arquivos (ex. Amazon S3) ou no HBASE. Abaixo está uma figura que descreve a arquitetura do Hive.

Para suportar schemas e partitioning o Hive deve manter os seus metadados em um banco relacional, podendo ser utilizado o Derby ou o MySQL. Ao inserir dados no Hive, caso haja violação nos tipos de dados do schema, o mesmo será gravado Null, não havendo interrupção da entrada de dados. O particionamento de tabelas (partitioning) permite aumentar a performance das queries executadas. As partições são armazenadas em diretórios diferentes, buscando otimizar o acesso na leitura do disco. Assim como os bancos relacionais suporta Joins e Outer Joins.
Fonte: http://www.devmedia.com.br/introducao-a-tecnologia-data-warehouse/27629#ixzz2top1xBBR http://www.macoratti.net/dwh_dmn.htm http://bigdatabrazil.blogspot.com.br/2013/07/hive.html
NoSQL
- Igor: 17/02
NoSQL são diferentes sistemas de armazenamento que vieram para suprir necessidades em demandas onde os bancos de dados relacionais são ineficazes. Muitas dessas bases apresentam características muito interessantes como alta performance, escalabilidade, replicação, suporte à dados estruturados e sub colunas.
O termo NoSQL foi usado pela primeira vez em 1998, como o nome de um banco de dados relacional de código aberto que não possuía um interface SQL. Seu autor, Carlo Strozzi, alega que o movimento NoSQL “é completamente distinto do modelo relacional e, portanto, deveria ser mais apropriadamente chamado ‘NoREL’ ou algo que produzisse o mesmo efeito”. Porém, o termo só voltou a ser assunto em 2009, por um funcionário do Rackspace, Eric Evans, quando Johan Oskarsson, da Last.fm, queria organizar um evento para discutir bancos de dados open source distribuídos.
Os atuais bancos de dados relacionais são muito restritos a isso, sendo necessária a distribuição vertical de servidores, ou seja, quanto mais dados, mais memória e mais disco um servidor precisa. O NoSQL tem uma grande facilidade na distribuição horizontal, ou seja, mais dados, mais servidores, não necessariamente de alta performance. Um grande utilizador desse conceito é o Google, que usa computadores de pequeno e médio porte para a distribuição dos dados; essa forma de utilização é muito mais eficiente e econômica. Além disso, os bancos de dados NoSQL são muito tolerantes a erros. Nele, toda a a informação necessária estará agrupada no mesmo registro, ou seja, em vez de você ter o relacionamento entre várias tabelas para formar uma informação, ela estará em sua totalidade no mesmo registro.
Os bancos NoSQL são subdivididos pelo seu núcleo, ou seja, como ele trabalha com os dados. Esses núcleos são Wide Column Store/Column Families, Document Store, Key Value/Tuple Store, Eventually Consistent Key Value Store, Graph Databases, Object Databases, Grid Database Solutions, XML Databases.
As data bases do tipo Wide Column suportam várias linhas e colunas, além de permitir subcolunas. Uma das databases desse tipo é o The Apache Cassandra. Ela provê uma escalabilidade linear, tolerância a erro em hardware por comodato ou infraestrutura da nuvem, além de suporte para replica em multimplos datacenters e baixa latencia. O modelo de dados da Cassandra oferece a conveniencia dos indices de colunas com a performace de "log-structured".
Outra data base do tipo Wide Column é o Hypertable. Ele é open source, tem suporte para Java, PHP, Python, Perl, Ruby C++, entre outros. Roda nas plataformas Linux e OSX. Além disso, conta com suporte 24/7/365 pela UpTime.
Referências: http://nosql-database.org/ http://en.wikipedia.org/wiki/NoSQL http://imasters.com.br/artigo/17043/banco-de-dados/nosql-voce-realmente-sabe-do-que-estamos-falando/ https://cassandra.apache.org/ http://hypertable.org/
Sistemas Distribuidos
- Hiago: 20/02 => Sistemas Distribuídos
Definiçao:
“Um sistema distribuído é um conjunto de computadores independentes entre si que se apresenta a seus usuários como um sistema único e coerente” – Tanenbaum/Van Steen
“Você sabe que existe um sistema distribuído quando a falha de um computador que você nunca ouviu falar impede que você faça qualquer trabalho” - Leslie Lamport
Middleware : camada intermediaria de software que gerencia os tipos diferentes de computadores trabalhando na base do mesmo sistema, é o responsavel por gerenciar sistemas distribuídos cuja computação é do tipo "Grade", ou seja, seus componentes são heterogeneos e necessitam de um controlador de recursos que diferencie a demanda e comunicação entre cada componente do sistema.
Vantagens:
- Acesso a recursos: o usuário independe de uma máquina especifica e local para acessar os dados e recursos de computação.
- Transparência: Todo o processo é transparente ao usuário de acordo com seu nível.
- Abertura : capacidade de acesso do usuário para melhorias, capacidade de expansão e manutenção.
- Escalabilidade: resume-se no tamanho, localização e administração.
Caracteristicas:
- Ausência de um relógio universal
- Sistemas autônomos de diferentes regiões
Tipos de computação em sistemas distribuídos:
- Cluster : hardware e software semelhante, utilizado em programação paralela
- Grade : componentes predominantemente heterogêneos embasando o SD e suas respectivas aplicações
Referências: http://pt.slideshare.net/fred_m/introduo-aos-sistemas-distribudos http://pt.wikipedia.org/wiki/Computa%C3%A7%C3%A3o_distribu%C3%ADda http://www.tlc-networks.polito.it/oldsite/anapaula/Aula_Cap01.pdf http://www.inf.ufsc.br/~bosco/ensino/ine5645/coulouris.pdf
Business Intelligence
- Fernando:24/02 => Business Inteligence
Business Intelligence (Inteligência empresarial) é um conjunto de teorias, metodologias, arquiteturas e tecnologias que transformam dados crus em informação útil e significativa para interesses empresariais. BI é reponsável por tratar quantidades enormes de dados desestruturados, de modo a ajudar a identificar, desenvolver ou criar novas oportunidades. De maneira simplificada, o BI é utilizado para tornar a interpretação de dados voluptuosos algo amigável. As tecnologias de BI são capazes por prover visões do passado, do presente e também preditivas das operações empresariais. É um método que possui o objetivo de auxiliar as empresas em estratégias de mercado e decisões considerando informações detalhadas. Além de um método, deve ser entendida como uma tecnologia que propicia a transformação dos dados em informação qualitativa. Essa tecnologia implica no uso de softwares de obtenção, armazenamento, análise e acesso para os objetivos específicos de cada negócio.
O termo foi criado pelo Gartner Group, uma empresa de consultoria e tecnologia da informação que provê tecnologia relacionada ao insight das empresas, buscando auxiliar os seus clientes a tomarem as melhores decisões no mercado. Não há uma estrutura bem definida de arquitetura BI, pois ela pode ser implementada de várias formas. Muitas tecnologias podem ser utilizadas para conceber uma solução BI. Entre elas estão o Data Warehouse (DW), o Data Mart, ODS, Data Mining, ETL e etc.. Na verdade o conjunto é muito maior. Geralmente aplicações de BI utilizam dados acumulados em data warehouses, que é outra tipica aplicação para auxiliar nas decisões empresariais baseadas em dados. Entretanto nem todas as aplicações de BI utilizam data warehouses e vice-versa. Em uma estrutura específica de BI, a arquitetura mais comum seria a composta pelo processo de ETL (Extração, Transformação e Carga), a tecnologia de DW (ou Data Mart) e ferramentas OLAP ou de mineração de dados (Data Mining).
Os benefícios do BI para as organizações são bastante numerosos, como se pode ver a seguir, entretanto as organizações ainda apresentam obstáculos para a sua implantação, não só pela falta de visão estratégica no mercado como também devido a uma barreira cultural. Normalmente as empresas tem preconceito com a tecnologia devido ao alto custo das aplicações com o surgimento da tecnologia, entretanto atualmente já existem soluções gratuitas que se demonstram bastante competitivas. Mesmo assim percebe-se que as 10 ferramentas mais utilizadas para BI são todas pagas.
- Tomada de decisão de forma mais pautada;
- Minimização de riscos;
- Utilização de fatos ao invés da subjetividade;
- Velocidade de respostas;
- Previsão através de tendências;
- Diminuição de custos;
- Aumento dos lucros.
BI não se refere simplesmente a uma técnica computacional de análise de dados, para que a tecnologia seja implantada com sucesso há a necessidade de um ajuste à empresa solicitante do BI, como por exemplo: Apoio da alta gestão: Com a falta de apoio da alta gestão empresarial teremos grandes dificuldades de, sequer, iniciar um projeto de BI. É a principal forma de conseguir a mobilização da organização para os objetivos do BI. Sem esse apoio, é necessário pensar muito antes de seguir em frente. Com o apoio já nos deparamos com várias barreiras, sem esse patrocínio as barreiras são praticamente intransponíveis.
- Identificação dos stakeholders: Conhecer os interessados do BI com antecedência permite elucidar as necessidades que o sistema deverá abordar. Sabendo quem são os stakeholders permitirá também a você obter uma maior compreensão de como lidar com possíveis ruídos e melhorar a comunicação entre os envolvidos.
- Levantamento de todos indicadores: É de grande importância conhecer todo o escopo de indicadores necessário ao projeto. O custo poderá ser alto se a necessidade aparecer lá na frente.
- Escolha de ferramenta: Ferramenta cara não significa a melhor ferramenta. Deve sempre ser analisado a ferramenta adequada para cada organização. Cada empresa tem característica diferentes uma das outras, logo as necessidades variam. Deve ser analisado o tamanho do projeto e da empresa, além do usuários e porte da organização. Todas a ferramentas tem um custo-benefício associado às diferentes empresas do mercado.
- Mapeamento correto da fonte dos dados: O mapeamento correto da origem dos dados permite a verificação da existência dos dados necessários para a geração do nosso maior insumo: informações. Sem a exatidão dessa etapa, todo o processo restante será prejudicado.
- Mobilização dos usuários: Por último, mas não menos importante, precisamos mobilizar os usuários da solução. Mas a mobilização não deverá ser apenas ao fim do projeto, e sim, no início e durante o processo também. É muito importante ter os feedbacks dos usuários, e ao mesmo tempo eles perceberem o valor do BI e a importância da aplicação em suas organizações. Podemos dizer que os usuários são "patrocinadores" importantíssimos, pois sem eles, o BI dificilmente conseguirá fôlego para prosperar na empresa.
As ferramentas mais utilizadas atualmente são WebFocus, SAP Netweaver, MicroStrategy, SAS, SAP Business Objects, IBM COGNOS, Board, ActuateOne, Oracle Hyperion e Microsoft BI Tools
Pentaho
A mais nova versão do programa conta com novas ferramentas para facilitar o seu uso por parte de usuários finais (comuns) e administradores. Para que isto ocorresse, o console de usuário foi totalmente reestruturado e agora pode ser altamente customizável.
Outra novidade da nova versão foi expandir a sua compatibilidade com plataformas de BigData, principalmente com o Hadoop. Além disso foi facilitado o trabalho com plataformas também de NoSQL, como o Cassandra, mas principalmente com o MongoDB.
Tentando solucionar casos de uso comuns, como otimizar a arquitetura de data warehouses, a nova versão do pentaho apresenta o primeiro driver de transformação de bases SQL em tempo real.
Vídeo divulgação nova versão:
http://www.youtube.com/embed/DQkSNOEm074
Referências
http://pt.wikipedia.org/wiki/Intelig%C3%AAncia_empresarial, http://www.binapratica.com.br/#!ferramentas-bi/c6rd, http://www.infoescola.com/administracao_/inteligencia-empresarial/, http://www.toolsjournal.com/articles/item/186-top-10-business-intelligence-and-analytics-tools, http://www.pentaho.com/5.0, http://blog.pentaho.com/2013/09/18/pentaho-5-has-arrived-with-something-for-everyone/
BigData
- Caetano: 27/02 => BigData
Podemos definir o conceito de Big Data como sendo conjuntos de dados extremamente grandes e que, por este motivo, necessitam de ferramentas especialmente preparadas para lidar com grandes volumes, de forma que toda e qualquer informação nestes meios possa ser encontrada, analisada e aproveitada em tempo hábil.
A partir da ultima década de 2000 houve uma crescente de dados exponencial que já preocupam os especialistas pela falta de espaço. Segundo a IBM em 2008 foram produzidos cerca de 2,5 quintilhões de bytes todos os dias e surpreendentemente 90% dos dados no mundo foram criados nos últimos dois anos, decorrente a adesão das grandes empresas à internet, como exemplo as redes sociais, dados dos GPS, dispositivos embutidos e móveis.
O Big Data se concentra nos 5 “Vs”:
- Os 5 “Vs”:
Volume: Quantidades de dados realmente grandes e que crescem exponencialmente
Velocidade: Tratamento dos dados (obtenção, gravação, atualização, ...) deve ser feito em tempo hábil - muitas vezes em tempo real.
Variedade: Dados de “tipos” diferentes, como imagens, áudios, vídeos e não apenas números e textos.
Veracidade: Processos que garantem o máximo possível a consistência dos dados.
Valor: determinar a relevância entre os grandes volumes de dados e como criar valor a partir dessa relevância.
O NoSQL faz referência às soluções de bancos de dados que possibilitam armazenamento de diversas formas, não se limitando ao modelo relacional tradicional. Bancos do tipo são mais flexíveis, sendo inclusive compatíveis com um grupo de premissas que "compete" com as propriedades ACID: a BASE (Basically Available, Soft state, Eventually consistency)
Mas, quando o assunto é Big Data, apenas um banco de dados do tipo não basta. É necessário também contar com ferramentas que permitam o tratamento dos volumes. Neste ponto, o Hadoop é, de longe, a principal referência.
Referências