Provas
- Datas
- 1a. Prova: 16/01/2014
- 2a. Prova: 06/03/2014
Notas
| Nome | 1a. prova | 2a. prova | Modelo Hierárquico | Comandos SQL | Novas Tecnologias |
|---|---|---|---|---|---|
| ................................ Pontuação | 25,0 | 25,0 | 10,0 | 25,0 | 15,0 |
| Caetano Alcantara Borges - 9169 9931 | 10,5 | - | - | - | - |
| Fernando Beletti - 9193 5335 | 14,0 | - | - | - | - |
| Hiago Araújo Silva - 9993-5786 | 16,0 | - | - | - | - |
| Igor Eduardo Leandro Alvarenga - 9103-7791 | 14,5 | - | - | - | - |
| Lucas Ramos Cardoso - 9276-0122 | 11,5 | - | - | - | - |
| Yassusshi Miguel Ávila Okada - 9178 2239 | 12,0 | - | - | - | - |
Trabalhos
1o. Trabalho - 10,0 pontos
- Criação de Banco de Dados Hierárquico com as funções CRUD
- Fernando: Conceito
- Hiago: Estrutura
- Igor: Inclusão
- Yassushi: Exclusão
- Lucas: Pesquisa
- Caetano: Alteração
Código Modelo Hierárquico
2o. Trabalho - 25,0 pontos
- Implementação de um Banco de Dados usando o SGBD abaixo:
- MySQL:
- Fernando: SMTC
- MySQL:

- Considerações:
- O diagrama é bastante simples, uma vez que o sistema é fortemente baseado em relatórios de fluxos e tempo de semáforos abertos. Estes dados são calculados a partir dos dados dos ciclos (tempos em que o semáforo fica aberto) e não é interessante guardá-los, já que devido à grande "rotatividade" do sistema, a todo momento estes relatórios são atualizados.
- Por exemplo, o tempo que um semáforo fica fechado não precisa ser salvo, já que basta fazer o complemento do tempo em que ele fica aberto (foco do sistema).
- Igor: Bus Route


- Oracle:
- Hiago: Kodificando
- Hiago: Kodificando
- Oracle:

- Lucas: Jarvas
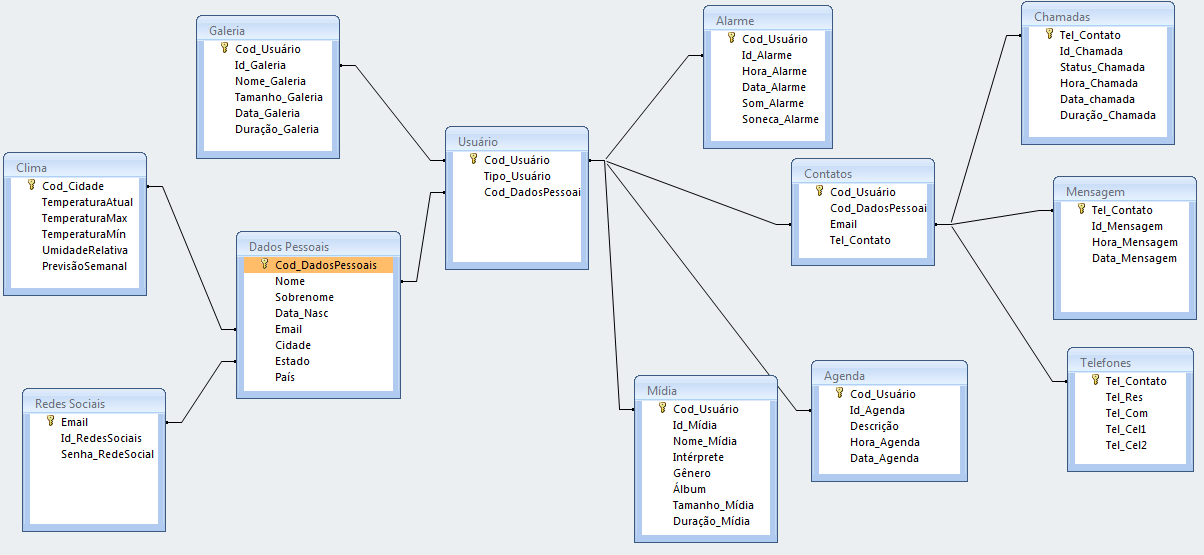

- PostgreSQL:
- Caetano: Game 2D
- PostgreSQL:

- Considerações:
- Em Save, o checkpoint é o local onde o usuário salvou o jogo
- Em Persongem, Item, Inimigo, o atributo imagem seria a imagem deles no jogo
- Em Item, o atributo Tipo_item, se refere se é uma arma, escudo, armadura, etc.
- Loot é onde informa os itens que o inimigo deixa ao personagem ao ser derrotado
- Em Inimigo, o atributo Experiencia_inimigo é a quantidade de experiencia que o inimigo dá ao personagem ao ser derrotado
- Com conexões e links se guarda as formas como os mapas estão ligados entre si
- Considerações:
- Considerações finais
- A forma de guardar todas as informações sobre o jogo, podem variar bastante de um jogo específico para outro. Esse DER apresenta uma forma mais geral, seguindo informações dadas pelo grupo desenvolvedor do projeto game 2D. Assim sendo, antes da implementação e principalmente da população do banco de dados, deve-se discutir se esse diagrama satisfaz o projeto com o grupo desenvolvedor.
- Considerações finais
- Yassushi: Salao de beleza

- Procedimentos:
- Avaliar 5W2H -> Ok
- Incluir Comentários -> Ok
- Desenhar DER - Diagrama Entidade Relacionamento => 30/01
- Implementar comandos do SQL => 10/02
- DDL
- Usar PostgreSQL, MySQL ou Oracle
- Criar todas as tabelas necessárias
- Especificar as chaves primárias (Primary Key)
- Aplicar os limites de cada campo (Constraints)
- Criar os índices mais relevantes (Index)
- Criar as views mais úteis (Views)
- DML
- DCL
- DDL
3o. Trabalho - 15,0 pontos
- Pesquisa sobre novas tecnologias
- Yassushi: 10/02 => Data Mining
Data Mining
Data mining ou em português mineração de dados, consiste em uma funcionalidade que agrega e organiza dados, encontrando neles padrões, associações, mudanças e anomalias relevantes. Ou melhor, é uma análise projetada com o objetivo de vasculhar uma grande quantidade de dados armazenados em depósito de dados, banco de dados ou outros repositórios de informação. Na maioria das vezes, são dados relacionados a negócios, empresas, mercado e pesquisas científicas.
O data mining pode ser divido em algumas etapas básicas que são: exploração, construção de modelo, definição de padrão e validação e verificação. E o resultado final da sua utilização pode ser exibido através de regras, hipóteses, árvores de decisão, etc. Uma mineração de dados bem executada deve cumprir tarefas como: detecção de anomalias, aprendizagem da regra de associação (modelo de dependência), clustering (agrupamento), classificação, regressão e sumarização. O processo de data mining costuma ocorrer utilizando dados contidos dentro do data warehouse.
O conceito de data mining é muitas vezes associado à extração de informação relativa ao comportamento de pessoas. Por esse motivo, em algumas situações, a mineração de dados levanta aspectos legais e questões relativas à privacidade e ética. Apesar disso, muitas pessoas afirmam que a mineração de dados é eticamente neutra, pois não apresenta implicações éticas. Dentre as etapas mais aprofundadas do Data Mining, podemos elucidar as seguintes:
Análise do problema: O processo de análise inicia a partir de um objetivo de busca, seguindo um determinado conhecimento; o principal objetivo é a possibilidade de selecionar os dados e definir as técnicas utilizadas na análise.
Preparação dos Dados: A preparação consiste em fases internas de coletânea de dados, avaliação, consolidação e limpeza, seleção dos dados e transformação.
-Coletânea de dados: Dados provindos de diversas fontes internas ou externas, como por exemplo de cartão de crédito;
-Avaliação: Exame sobre os dados colhidos com o objetivo de identificar características do modelo da cada informação.
-Consolidação e limpeza: Construção de base de dados a partir de correções de erros, remoção de registros e inserção de valores comuns em campos vazios.
-Seleção de dados: É a seleção de dados específicos para cada modelo de dado, como a seleção de variáveis em colunas ou dependentes.
-Transformação: Ferramenta escolhida para redirecionar a apresentação dos dados.
Modelagem: Definição de tarefas e técnicas utilizadas sobre a ação de cada algoritmo, etapa que gera um modelo a ser analisado posteriormente.
Análise e validação de resultados: Considerando que um modelo válido nem sempre é um modelo correto, visa detectar o que há de implícito num modelo, e o que nele é mais peculiar na precisão de uma informação.
Exemplos Aplicação:
Wal- Mart
Embora recente, a história do data mining já tem casos bem conhecidos. O mais divulgado é o da cadeia americana Wal-Mart, que identificou um hábito curioso dos consumidores. Há cinco anos, ao procurar eventuais relações entre o volume de vendas e os dias da semana, o software de data mining apontou que, às Sextas-feiras, as vendas de cervejas cresciam na mesma proporção que as de fraldas. Crianças bebendo cerveja? Não, uma investigação mais detalhada revelou que, ao comprar fraldas para seus bebês, os pais aproveitavam para abastecer o estoque de cerveja para o final de semana.
Bank of America
Há quem consiga detectar fraudes, cortar gastos ou aumentar a receita da empresa. O Bank of America usou essas técnicas para selecionar entre seus 36 milhões de clientes aqueles com menor risco de dar calote num empréstimo. A partir desses relatórios, enviou cartas oferecendo linhas de crédito para os correntistas cujos filhos tivessem entre 18 e 21 anos e, portanto, precisassem de dinheiro para ajudar os filhos a comprar o próprio carro, uma casa ou arcar com os gastos da faculdade. Resultado: em três anos, o banco lucrou 30 milhões de dólares.
Telecomunicações
Atualmente, em telecomunicações, existe uma explosão nos crimes contra a telefonia celular, dentre os quais, a clonagem. Técnicas de data mining podem ser utilizadas para detectar hábitos dos usuários de celulares. Quando um telefonema for feito e considerado pelo sistema como uma excessão, o programa faz uma chamada para confirmar se foi ou não uma tentativa de fraude.
Administração em Alto Nível
Depois do final da segunda guerra mundial a Pesquisa Operacional (P0) apareceu como ferramenta fundamental para a vitória das tropas contra as potências do eixo. Com a pesquisa operacional foi possível resolver matematicamente o problema de alocação ótima de recursos e isto vem sendo utilizado com grande sucesso em altos níveis de decisão até o presente momento. Cerca de cinquenta anos depois, apareceu o data mining.Suas potencialidades estão longe de serem imaginadas e não seria ousado esperar que no mundo globalizado possa vir a dar seus frutos como a PO deu no passado.
Medicina
Atualmente as técnicas de data mining são pouco usadas em medicina. No momento, o ponto que está emperrando o uso de data mining é o fato de que data mining sendo uma nova concepção dirigida para pesquisa ainda é quase completamente desconhecida da comunidade médica. Ora, se existem dados clínicos abundantes, estes dados são frequentemente adequados a um estudo de data mining por não conterem dados que aparentemente são inúteis mas que são exatamente os que o pesquisador de data mining procura.
- Lucas: 13/02 => DataWarehouse
- Igor: 17/02 => NoSQL
NoSQL
NoSQL são diferentes sistemas de armazenamento que vieram para suprir necessidades em demandas onde os bancos de dados relacionais são ineficazes. Muitas dessas bases apresentam características muito interessantes como alta performance, escalabilidade, replicação, suporte à dados estruturados e sub colunas.
O termo NoSQL foi usado pela primeira vez em 1998, como o nome de um banco de dados relacional de código aberto que não possuía um interface SQL. Seu autor, Carlo Strozzi, alega que o movimento NoSQL “é completamente distinto do modelo relacional e, portanto, deveria ser mais apropriadamente chamado ‘NoREL’ ou algo que produzisse o mesmo efeito”. Porém, o termo só voltou a ser assunto em 2009, por um funcionário do Rackspace, Eric Evans, quando Johan Oskarsson, da Last.fm, queria organizar um evento para discutir bancos de dados open source distribuídos.
Os atuais bancos de dados relacionais são muito restritos a isso, sendo necessária a distribuição vertical de servidores, ou seja, quanto mais dados, mais memória e mais disco um servidor precisa. O NoSQL tem uma grande facilidade na distribuição horizontal, ou seja, mais dados, mais servidores, não necessariamente de alta performance. Um grande utilizador desse conceito é o Google, que usa computadores de pequeno e médio porte para a distribuição dos dados; essa forma de utilização é muito mais eficiente e econômica. Além disso, os bancos de dados NoSQL são muito tolerantes a erros. Nele, toda a a informação necessária estará agrupada no mesmo registro, ou seja, em vez de você ter o relacionamento entre várias tabelas para formar uma informação, ela estará em sua totalidade no mesmo registro.
Os bancos NoSQL são subdivididos pelo seu núcleo, ou seja, como ele trabalha com os dados. Esses núcleos são Wide Column Store/Column Families, Document Store, Key Value/Tuple Store, Eventually Consistent Key Value Store, Graph Databases, Object Databases, Grid Database Solutions, XML Databases.
Referências: http://nosql-database.org/ http://en.wikipedia.org/wiki/NoSQL http://imasters.com.br/artigo/17043/banco-de-dados/nosql-voce-realmente-sabe-do-que-estamos-falando/
- Hiago: 20/02 => Sistemas Distribuídos
- Fernando:24/02 => Business Inteligence
- Caetano: 27/02 => BigData